 前端性能优化
前端性能优化
# 性能问题的起点
# 不要盲目去进行性能优化
我们要意识到,前端性能问题,和后端性能问题不同,本质上,前端的性能问题都是渲染性能问题,当然,引起渲染性能损耗的可能是对渲染原理的不懂,也可能是我们写了不好的代码。但是归根结底,我们还是要掌握浏览器渲染原理,才能写出符合起原理的好代码。
# 性能问题的分类
我们从引起性能损耗的原因出发对性能问题进行分类:
- 加载性能问题
- 渲染性能问题
- 内存性能问题
- 算法性能问题
- 设计性能问题
其中,内存性能问题指由于程序内存占用过多而被耗尽导致的性能问题,虽然从很多角度讲算法性能问题可能也是内存性能问题,但是我们这里着重想指出由于代码使用不当导致内存泄露的问题,而算法性能问题是指代码设计上没有考虑到运算的复杂度,导致的计算资源占用过多(一般指CPU计算资源)带来的问题。
设计性能问题其最终可能还是会落回内存或算法的性能问题,但是这里着重强调,由于架构、处理办法等的设计不足,带来的整体性的性能问题,例如整体层面设计了缓存与未使用之间的差异,例如模块代码分层组织与结构混乱之间的差异。通常来讲,设计性能问题是大面积代码整体起效果,而不是某一处局部代码本身的问题。甚至有可能是底层依赖的问题,而换一个底层依赖,则需要对整个项目进行重构。例如使用webpack和vite就是会存在巨大的差异,但是如果想从webpack迁移到vite,则需要耗费一些精力进行重构。
# 建立性能指标体系
建立性能指标体系,我们遵循“第一次原则”和“持续性原则”。第一次原则指用户在第一次打开应用时,以更快的速率获得自己想要的内容;持续性原则指在用户使用应用过程中,没有卡顿的获得自己想要的内容。
以前我们在考虑如何让用户更快的获得内容时,往往只关注加载和渲染的效率,但近几年开始,关注用户体验逐渐取代了传统思维。如果只关注效率,实际上我们无法获得准确的性能指标数据,而关注用户体验,我们可以细化指标,从而排除那些其实不太重要的影响部分。
优化用户体验质量是网络上任何网站取得长期成功的关键。无论您是企业主、营销者还是开发者,Web Vitals (opens new window) 都可以帮助您量化网站体验并发现改进机会。
网页指标是 Google 推出的一项计划,旨在针对提供出色网络用户体验至关重要的质量信号提供统一指南。
# First Contentful Paint (FCP)
“第一次内容绘制”,也就是指用户从打开应用到肉眼可以看到界面上第一次呈现出内容的时间。这里的内容可以上任何界面呈现,文本、图片、视频等等。

上图中第二个界面为第一次出现内容,即FCP
通过FCP这个指标,可以反映用户对应用打开速度的感知程度。FCP越小,说明用户能够感知你的应用打开速度更快,对你的应用竖起大拇指。
# Largest Contentful Paint(LCP)
“最大块内容首次绘制”,也就是从你的应用打开,到全部内容加载完成之前,这一段时间里面,界面上最大的一块内容在什么时间点上被完整渲染出来。LCP是一个动态的评价过程,因为当界面没有加载完之前,你也说不准到底哪一块才是界面上最大的一块内容。例如下面这个例子:




不同时间点上界面上最大的内容块并不是一成不变的,只有当界面加载完毕趋于稳定时,我们才能确定LCP
LCP从另外一个角度去评价了应用的打开速度,因为即使FCP很快,但如果LCP慢的话,仍然意味着你的应用体验不佳。
# First Input Delay(FID)
“第一次输入延迟”,即用户第一次在界面上进行操作(例如点击某个链接)到程序对这个操作做出回应的延迟。这是因为经常我们的应用需要通过网络请求脚本或数据来进行渲染,而在请求的过程中,我们的程序或者浏览器本身,无法响应用户的操作,这个无法响应的过程,就是FID。例如某些点击我们通过脚本中的事件监听来处理,但是此时脚本还在加载过程中,所以点击就没有任何效果。

上图中,黄色条代表主线程中正在执行的某个任务,如果用户在这个任务的执行过程中进行了某次输入,那么浏览器是无法响应的,它必须等到这个任务结束才能响应
FID 只关注来自离散操作的输入事件,如单击事件、按键事件, 像滚动和缩放这样的连续交互动作是不考虑的。

用于应用的交互性非常重要,因此,FID实际上反映了你的应用从打开之后阻塞用户进行交互的时间,因此是一个非常重要的负面指标。
# Time to Interactive(TTI)
“达到可稳定交互的时间”,假如你不做任何输入,让应用自己打开,知道整个应用没有发生任何动作(静默状态)持续5秒钟,那么在这5秒钟之前的那一次长任务的结束时间,就是TTI。

上图中黄条是长任务,和FID示意图中的黄条意思相同。当加载达到稳定静默状态(没有黄条)5秒钟后,往前找到最后一个长任务的结束时间,这个时间就是TTI。由于静默状态的存在,我们认为TTI之后的所有时刻,都是可稳定交互的,不会出现FID中所指出的不可交互的问题。
通过TTI和FID的结合,可以评判出你的应用在什么的交互体验如何。比如,当你打开一个网站之后,已经感觉整个渲染完成了,但是怎么点链接都没有响应,这种用户体验明显不好。比如前两年流行的SSR技术,虽然用户看到的界面的时间变短,但是由于它消耗了第一次渲染的过程时间,之后在去拉脚本下来,才能交互,所以TTI可能并不够好。
# Total Blocking Time(TBT)
“总阻塞时长”,长任务执行会阻塞界面的渲染,有的卡顿明显,有的不明显,在FCP到TTI之间,这些长任务的阻塞时长的总和,就是TBT。

图中黄红块就是长任务,红色就是阻塞时长(超过50ms部分),红色部分的总和就是TBT
我个人认为TBT是统计意义上的指标,它不像FID、TTI之类的指标那么直指本质,但是一般来讲,统计意义上的指标更具有数学意义,包含的更多的内涵。
# Cumulative Layout Shift(CLS)
“累计布局偏移”,它是一个比值。在应用界面加载过程中,可见元素在前后两帧之间存在布局上的偏移,那么认为这个元素是不稳定的,比如用户准备用鼠标去点这个元素,结果点击点时候,这个元素被另外一个元素顶开了,导致点错了元素。CLS就是收集一段时间内这些偏移的数据。它的计算公式是
layout shift score = impact fraction * distance fraction

在上面的示例中,左侧(也就是前一帧)图片内的元素占据了视口的一半区域,右侧(也就是后一帧)图片内的元素向下移动了视口高度的 25%。红色虚线框表示的就是这两帧中元素可见区域的并集,也就是 75%, 所以 impact fraction 就是 0.75。最大的视口尺寸是高度,不稳定元素移动了视口高度的 25%,因此 distance fraction 就是 0.25。最后可以得到布局移位就是 0.75 * 0.25 = 0.1875。

我个人认为CLS是人为制造的一项指标,它通过比较复杂的设计,来计算一个值作为衡量标准。当然,它的初衷是衡量页面元素在布局层面的稳定性,如果你的应用元素在布局上跑来跑去,体验当然是不好的。
# Frame Per Second(FPS)
“每秒帧数”,它是一个速度指标“帧率”,即在每秒内刷新了多少帧。我们都知道浏览器会根据应用的变化来按照一定的帧率刷新页面,但是浏览器的刷新和电脑屏幕的刷新是两件事,电脑屏幕按照固定的刷新率进行刷新,而浏览器则是按照一定的(不稳定的)频率进行整个可视窗口的绘制。浏览器的绘制受多方面的影响,理论上在没有任何影响下,浏览器的帧率60Hz,即16.6ms左右一帧,但是由于浏览器执行时存在一些资源调度逻辑,需要等某些执行任务完成之后,才能进入下一帧刷新,这也就导致了丢帧现象,我们都知道人肉眼可辨为0.1s每帧,超过这个时长就会感觉卡顿,所以通过FPS指标来衡量应用的性能也是非常重要的。
前面所有的指标,都是基于“第一次原则”建立,只有FPS是基于“持续性原则”。虽然前面的指标那么多,但是,实际上我们在日常开发中,更常见的是卡顿现象,而第一次加载的性能问题,往往核心的问题都在于网络不够好,但是卡顿,甚至死循环导致浏览器卡死,却常常是我们写代码造成的。因此,FPS指标我认为对我们日常开发更重要。
# 前端性能监控
在建立了性能指标体系之后,我们就可以基于这些指标建立前端性能监控。我们可以通过不同的工具来达到我们的监控目的,主要有两个方面:
- 基于浏览器已经提供的工具,例如devtools
- 自建监控系统
在开发测试阶段,我们主要依赖浏览器提供的工具进行性能问题的诊断和排查,这部分将在下一节详细介绍。而当产品上线之后,我们需要将指标数据上报到监控平台,为后续做数据分析做好准备。
在前端收集性能数据时,我们常常会用到如下接口:
- perfermance
- PerformanceObserver
- web-vitals
通过巧妙使用上面的对象、库,我们可以比较便捷的收集到和性能相关的数据,并上报给监控平台。
# 诊断性能问题的方法
监控往往是对已经在生产环境运行的应用进行,而我们在开发、测试时发现性能问题,则需要我们拥有顺藤摸瓜,找出性能问题根源的能力。当然,前文我们对性能问题进行分类的依据也是从造成性能损耗的原因出发进行分类的,因此,其实我们可以有目的的对性能问题进行排查,按照问题分类进行排除的方法,逐渐找到根源。但是,我认为排除法的效率比较低下,我们应该找到更好的方法来解决。
# 可视工具诊断
我们可以借助chrome浏览器自带的devtool可视工具进行诊断。其中主要用到Performance、Lighthouse两个面板工具。Performance面板提供应用运行过程中的时间切面,是动态的实时的快照收集。Lighthouse则是一个基于谷歌评价指标的全站评测工具,其中不仅包含了性能指标,还包含了其他指标,我们可以只关注其中的性能指标,通过lighthouse,我们可以获得对自己网站的一份评测报告。
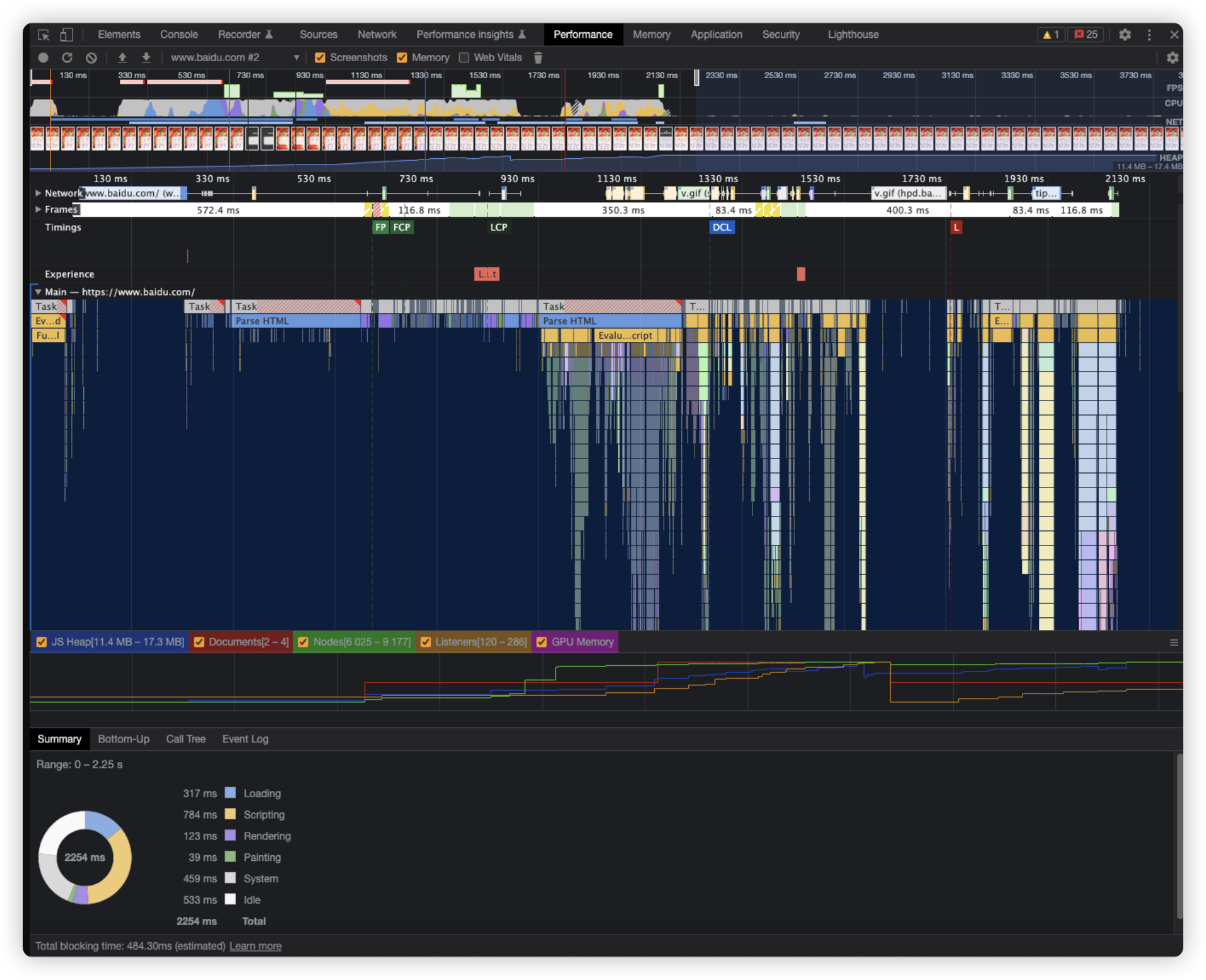
Performance面板基于时间线timeline对应用运行过程进行了切面汇总,创造性的绘制了一张火焰图,通过这张火焰图,可以直接定位到哪一段代码运行了特别长时间
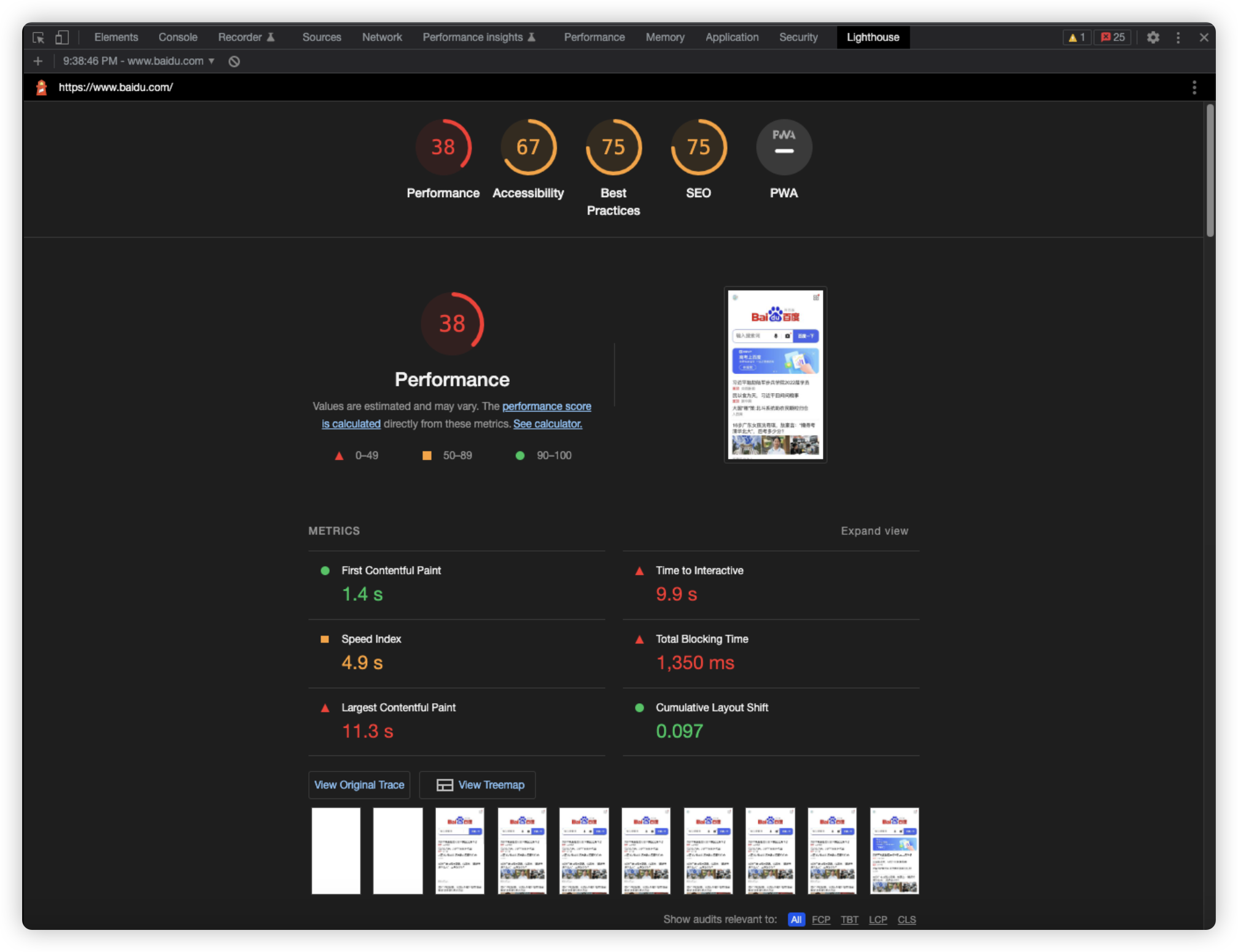
Chrome60直接内置了Lighthouse到devtool面板中,它基于谷歌指标直接对站点整体进行打分,不需要我们自己去建立指标
其中Lighthouse覆盖了很多我们上文提到的指标,还有SEO的指标评价。但是对于我个人而言,更推荐用会、用懂、用熟、用精Performance面板,因为我们日常开发中更多的时候并不需要在意上面的FCP、TTI等等指标,我们往往更关心的是代码运行性能,而Performance面板就可以为我们提供非常有帮助的信息。
如果你需要一个成熟的性能监控平台,市面上有很多。
2、灯塔
4、神策
# 阿里ARMS基本使用





# Sentry




//安装
npm install --save @sentry/react
//项目中配置SDK
import * as Sentry from "@sentry/react";
Sentry.init({
dsn: "https://e19d714e725e453caac128286a1f0645@o4505508596350976.ingest.sentry.io/4505508608278528",
integrations: [
new Sentry.BrowserTracing({
// Set 'tracePropagationTargets' to control for which URLs distributed tracing should be enabled
tracePropagationTargets: ["localhost", "https:yourserver.io/api/"],
}),
new Sentry.Replay(),
],
// Performance Monitoring
tracesSampleRate: 1.0, // Capture 100% of the transactions, reduce in production!
// Session Replay
replaysSessionSampleRate: 0.1, // This sets the sample rate at 10%. You may want to change it to 100% while in development and then sample at a lower rate in production.
replaysOnErrorSampleRate: 1.0, // If you're not already sampling the entire session, change the sample rate to 100% when sampling sessions where errors occur.
});
const container = document.getElementById(“app”);
const root = createRoot(container);
root.render(<App />)

# 一些名称的解释
# 监控SDK
通过上面两个现成的框架,大家也大致能看出,我们前端监控到底是要干什么事情
页面的性能情况:包括各阶段加载耗时,一些关键性的用户体验指标等用户的行为情况:包括PV、UV、访问来路,路由跳转等接口的调用情况:通过http访问的外部接口的成功率、耗时情况等页面的稳定情况:各种前端异常等数据上报:如何将监控捕获到的数据上报
其实完整的监控平台至少分为三大类
- 数据采集与上报
- 数据整理和存储
- 数据展示
而上面总结的那一大堆,主要就是监控SDK的实现,SDK,其实就是Software Development Kit,其实就是提供实现监控的API
# 前端埋点
无论性能,行为还是异常情况,我们都需要在需要监控的项目代码中去监听这些内容。那么具体监听的手段其实就被称之为前端埋点。
前端埋点还分为手动埋点和无痕埋点。
手动埋点,就是在要监听的项目中的某段代码或者某个事件中加入一段监听SDK代码,然后对监听的内容进行上报,好处就是可以对关键性行为做出具体的跟踪,坏处是具有侵入性
无痕埋点,就是就是对监听的项目进行全部无脑监听,比如点击事件,滚动事件等等,只要触发了就上报。好处就是对代码没有侵入性,坏处当然也很明显无法快速定位关键信息,上报次数多,服务器压力大
# 浏览器资源加载原理
# 一道面试题:从你输入url开始……
请问从你输入url开始到你看到界面,浏览器在背后都发生了哪些事?
这道面试题似乎都有标准答案了,为什么面试官们还是乐此不疲的问面试者呢?因为即使你是死记硬背下来答案,也能帮助你理解浏览器加载资源到渲染界面这个过程中所做的事情。这道题的答案可以分为4个部分,接下来我们将会回答这道面试题的2/4部分。
# 浏览器加载资源的流程
当浏览器与被请求的服务器建立http连接之后(被请求资源类型基于http头信息进行协商),被请求页面的html字符串被服务器端以字节流的形式向浏览器发送,浏览器在接受到字节流之后,会将其根据编码转换为字符串,接着根据W3C的HTML标准对字符串进行解析(生产tokens),经过此法分析后将tokens转化为有命名、属性及属性值的嵌套对象结构,并根据结构关系连接处属性结构,最终生成DOM树。
于此同时,在生成DOM树的过程中,浏览器会对一些特殊的对象进行特殊的处理,其中遇到link[rel=stylesheet], script[src], img[src]等指向其他资源的对象时,会采用策略再次请求对应资源。其中,link css的加载过程和html的加载过程很像,也会进行令牌->CSSOM的类编译过程,而且其中遇到@import, url()等还会再次分出支流去请求资源。
这些分出的支流资源请求行为模式并不相同,其中script大部分都是同步加载的,会阻塞渲染(哦,我们还没有讲到渲染),一边加载一边执行,而其他资源常常是异步的,只有当他们都加载完毕之后才会使自己生效。另外,iframe是一个特例,你不能用引用资源来解释它。我们可以为script设置delay或defer属性来让script延迟加载,这一就不会阻塞DOM的第一次渲染动作。
由于网络请求不属于浏览器当前页面的渲染任务,所以它们被放在另外一个线程中运行,当请求结束后才会把请求到的资源交还给主线程去使用。(下文我们会详细阐述浏览器的渲染线程、JS引擎等。)而以前的浏览器,对这些正在发送的请求总数有一个限制,不同浏览器限制不同,通常我们说6个是它的最高配额,也就是说如果我们的页面上有10张图,它们会被分两批进行请求,所以当页面里面的图片多的时候,我们需要考虑一些策略来决定怎么加载,比如采用懒加载策略,避免图片请求撑爆了请求配额,导致用户点击动作出发的数据请求无法即时响应。
当DOM树被加载完成时(包含同步执行的script),DOMContentLoaded事件会被触发。当其他被依赖的资源(如css、图片)加载完成时,load事件被触发。这里需要注意“被依赖”,如果css、img是通过script延迟异步创建加载的,那么是不被包含在load事件所指代的过程里面的。但css引入了其他资源,则会被包含在这个过程中。
理论上,构建DOM树和渲染应该是分开的,我们思考时可能想应该先有DOM树,然后把DOM+CSSOM放在一起,才能做渲染,但是浏览器偏偏没有这样做,而是在DOM树的加载过程中,就一边加载一边渲染。这也是为什么有些网站css加载完之前和加载完之后会有明显的差异的原因。还有一些老的技术,基于流的特性,让html永远处于加载状态,这样就可以让服务器端异步的吐出内容来进行页面加载,比如一些古老的聊天室就是基于这样的技术实现实时聊天的,要知道那个时代还没有ajax技术。
# 哪些加载会阻塞渲染?
正如上文所说,阻塞渲染并不是一定的,例如script理论上会阻塞,但是我们可以通过defer属性来延迟它的加载,从而避免阻塞,但是一些场景下,又不能延迟其加载,否则会使得TTI、CLS数据很不好看。异步加载的img理论上不会阻塞渲染,但是当页面里面图片多了,也可能由于请求过多导致服务器瞬间承担了较强的压力,而让html的流吐出变慢。
Css加载不会阻塞DOM树的解析,但css加载会阻塞渲染,在下文我们会详细讲解浏览器的渲染原理。其实我们可以很容易理解这一点,因为渲染不单单只有DOM树,而是DOM+CSSOM一起,而加载css会让CSSOM的加载和计算都延长。这是怎么发生的呢?下文讲到浏览器渲染原理时,我们会详细阐述。
# 加载优化技巧
加载优化的目标,是让用户打开我们的应用更快,减少TTI。也就是说,这一优化针对的是“第一次原则”,及减少用户打开应用到开始使用应用提供的功能之间的时间消耗,让用户更快的使用应用实现自己的目的。当然,我们业界有这样一句口号,“追求极致体验”,很多厂商强调0.1s级别的应用打开,但我认为这是没有必要的,过于追求极致是有代价的,代价就是浪费丰富的服务资源来支撑这一0.1s的性能,摩尔定律会让我们在这种追求极致的过程,没提升一点点的成本都极高。我认为只要不慢,就是我们的目标。因此,我们虽然在下文会提供一些技巧,但是这些技巧可能你并不一定非得都用上,因为有的时候,即使你把这些技巧全部都用上,或许也看不到任何的性能提升,最后还不如加几台服务器,购买更高级别的宽带来的快。这里只是提供一些技巧作为参考,你可以从中掌握一些成本较低的方案,但最终还是需要整体来考虑。
# 优先级加载顺序
我们既然知道浏览器的加载流程了,那么我们就应该设计我们的加载顺序,以更好的把最早需要的部分加载出来,让暂时不需要的部分在空闲的时候加载。一般来讲,我们会推荐如下的加载顺序:
- 在head中加载css文件,因为css是异步加载的,不会阻塞渲染,同时把它放在顶部,是希望它可以尽早发出请求,当DOM加载完时,我们希望CSSOM也同时加载好,两者再reflow一回
- 在body结束位置加载script文件,因为script会阻塞渲染,如果在前面加载,就会让网页渲染到一半停滞,等script执行完毕之后才会继续渲染
浏览器会对资源的重要性进行判断来划分加载优先级,通常有Lowest, Low, High, Highest四个等级,一般在
中的css具有Highest最高优先级,其次是<script>,但当<script>拥有defer或delay属性时,其优先级会降低为Low。这也就意味着,在浏览器中,不同资源出现在同一位置的时候,其加载的顺序并不一定按照其出现的先后顺序决定,而受到资源类型的优先级影响。有些优先级规则比较隐蔽,比如图片处于可视区域和非可视区域的优先级,明显是处于可视区域的优先级更高。 # 预加载
当有些资源的加载优先级不符合你的预期时,可以通过预加载preload来提升其优先级,让它尽快加载。比如某些css文件,在首屏渲染时可能并不会用到,但是当鼠标滚动下滑时,会被加载到页面中,但是我们知道请求过程是需要时间的,此时,往往我们已经通过脚本修改了DOM,但是对应的css还处于加载状态,页面上的元素就并没有被应用样式,等到css加载完毕之后,才会重新渲染。这样的体验明显不够好,于是,我们可以在
中使用预加载来让浏览器提前准备好对应的css资源,等到需要它的时候,我们就不需要再次请求它。<link rel="preload" as="sytyle" href="some.css" />
除了css,图片、视频等也经常被预加载。被预加载的资源,会被浏览器提前下载到本地,当下一次请求该资源时,就直接使用请求好的资源。从这一描述中你会发现,这类资源一定是固定的,幂等的,多半是静态资源,例如脚本文件、css文件、图片等等。像数据接口之类的资源,是不应该使用预加载的。
# 预请求
预请求prefetch相当于在实际发生请求之前,让浏览器提前帮你做一次相同的请求,而这些请求往往是静默的,不被察觉的。例如,你的网站有两个页面,用户进入第一个页面之后,一定会通过点击进入第二个页面。但是假如每次都需要进入的时候再来加载这个页面,那么就会消耗掉请求这个过程时间,通过prefetch我们就可以让浏览器悄悄先请求一次第二个页面,并通过缓存机制,将第二个页面缓存起来,这样当用户点击进入第二个页面时,就可以做到秒开。
<link rel="prefetch" href="page2.html" />
和preload有很大不同,一是prefetch可以预请求任意资源,而非仅仅静态资源;二是prefetch的效果和人为手动请求效果一致,所以当你的页面再次请求对应资源的时候,请求还会再发出,也就是说,同一个资源,prefetch一次,人为请求一次,有两次。有两次请求显然又有它的缺点,因此,一般来说,可被预加载的资源,我们都需要服务器端配合设定浏览器缓存(在后文会详细阐述),这样才能在下次请求时瞬间获得资源结果。
一个技巧是,我们可以通过JS脚本动态插入<link rel="prefetch" />来实现预加载,例如当我们鼠标移动带某个链接时,就对该链接指向的资源进行预请求,当用户点击时,实际上我们对该链接对应资源的请求早都发出去了,可能此刻已经被缓存起来了,等到点击发生时,就可以瞬间打开该链接了。
除了link标签的preload与prefetch之外,script标签还有一些属性会影响性能
async:异步加载外部脚本文件。当设置了async属性后,脚本文件会并行于页面的加载进行下载,并且会在下载完成后尽快执行。这意味着脚本的执行可能会在页面解析完成之前,也可能之后,具体取决于脚本下载完成的时间。async属性对于不依赖其他脚本或文档内容的脚本特别有用,因为它减少了页面渲染的阻塞时间。defer:延迟执行外部脚本文件。当脚本有defer属性时,脚本的下载将和页面解析并行进行,但脚本的执行会延迟到整个文档都解析完成后。这对于那些需要等待整个页面解析完成后才能运行的脚本很有用,比如一些依赖于DOM的脚本。
# 懒加载
和预加载相反,懒加载是降低请求优先级的技术。不过除了<script>的defer之外,<img><iframe>等支持loading属性,把loading值设置为lazy,其效果和<script>的defer就非常接近。虽然原生支持lazy loading,但是我们必须考虑浏览器请求数限制问题,假如一篇文章有几十张图片,那么这些图片的请求就会在文档加载完之后被发出,这也就意味着如果用户点击某个按钮需要发出一个请求时,这个请求就会被前面几十张图片的请求给拦住,必须排队等着。因此,我们常常需要自己设计懒加载策略。
以图片为例,我们往往会用一张placeholder图作为占位符,多张图都是用占位图,配合上缓存,就会直接展示在界面上,当该图片实际进入可视区域时,再将<img>的src属性替换为真正要加载的图片的地址,此时图片才会被加载。有两种方案可以知道图片是否在可视区域,一种是通过监听scroll事件,实时去计算每张图片当前的位置;另一种是利用IntersectionObserver来对图片进行监听。
# 代码打包与分包
既然代码的加载影响了应用的打开速度,那么我们就要想办法让代码的加载变快。我们的策略是把需要的代码合并尽早加载,把不需要的代码延迟加载。
# 构建打包
我们前文提到,浏览器的请求数量有上限,因此,我们就可以想办法把多个请求合并为一个,虽然单个请求的时长会增加,但是相比于分批请求所带来的网络性能损耗,反而会获得更好的表现。因此,把原本分散在多个文件中的代码合并到一个文件中。
最早的土办法就是手动把代码拷贝到一起;之后出现了一些工具,不仅可以自动把代码粘接在一起,还能增加一些包装代码,例如当年jQuery所做的一样;再到后来出现了webpack, rollup等构建打包工具,把打包抽象到了一个非常高的高度,它们内部基于AST去处理代码,不仅可以把原本分散在多个文件的代码打包在一起,还能做一些代码层面的检查和优化。
如今,代码构建已经成为前端项目工程化的一部分。各类前端框架也都必须在构建工具的加持下才能使用。
# 分包
但随着前端代码量的越来越大,在打包成为主流之后,我们又开始发现,如果一个项目的代码必须全部打包到一个文件,那么这个文件可能撑到很大很大,其下载的时长突破了通过打包减少请求数量所带来的收益,导致应用打开速度变慢,而且由于我们现在的应用都是基于脚本实现的界面渲染,所以,用户会有更长的时间无法看到界面无法进行交互。但由于构建所带来一些好处,我们无法再回到以前那种纯粹通过粘连代码在一起的方案来实现打包了。于是,基于webpack等构建工具等chunk机制应运而生。
这种chunk机制可以让开发者自己定义哪些代码需要被从主包中提取出来放到一个chunk中,这样,应用在加载时,就能利用并行加载的特点,同时加载两个文件,把脚本的加载时间缩短。等下我们会讲到模块化加载,chunk机制的加载其实也是模块化的加载原理,但和纯粹的模块化开发存在巨大差别。
# 按需加载
和前文提到的懒加载一样,js脚本的加载也可以实现懒加载,即需要的时候,才加载进来执行,不需要的时候按兵不动。这一设想在浏览器端最早被AMD模块化加载机制实现,其对应的实现库叫requrejs,现在已经很少有人在用了,但是在ES5和webpack等工具出现之前,是前端架构中的一个主流。
AMD模块化规范要求开发者们按照一定的结构撰写代码,每个要实现的功能放在一个模块中,通常情况下,一个模块放在一个文件中,这个文件被称为模块文件,基于文件路径加载该模块。有了这些前置规范之后,开发者们使用requirejs作为AMD的驱动框架,在主应用中加载入口文件,只有当前界面所需要的模块会被加载,当前界面不需要的模块文件按兵不动,等到新界面出现时,被需要的模块文件会被请求并加载。
随着ES6的发布,以及浏览器的支持,原生的import可以在浏览器中直接使用了。我们不再需要requirejs等第三方库,就可以方便的实现模块化开发。
虽然按需加载确实可以减少首次加载的代码量,但是这里有一个陷阱,假如我们把模块切分的很细(以方便复用),那么应用打开时就有可能依赖非常多的模块,导致突破请求数量上限,降低了加载的性能。因此,我们仍然需要webpack来实现打包,通过打包分包,来避免首次需要加载过多文件数量的问题。
同时,随着新版本的ES的发布,import()可以帮助我们在原有import模块化标准的基础上,按需加载。同时webpack也支持将import()的目标脚本作为一个chunk独立出来。这样,我们不仅能享受打包带来的减少加载文件数量的优化效果,还能享受通过chunk分包实现按需加载的效果。
# 优化资源体积
既然我们已经知道,网络传输会影响应用的打开速度,降低用户体验,那么,我们为何不想办法减少传输的过程呢?怎么办到呢?我们可以想办法减小资源的体积,从而可以减少传输量,减少传输的时间呀。
# 代码压缩
我们使用webpack时,可以通过mode为production配置来让webpack自动压缩我们的js代码,但是由于webpack并不能处理我们的css,所以我们必须通过其他插件来压缩css、svg、json等等其他可以作为代码的资源。
除了对代码进行压缩,我们还可以通过工具链移除、优化代码,从而获得更小体积的结果。例如,通过tree shaking的特性,移除哪些没有被调用的js函数,移除那些没有被引用的css类,移除那些用来注解的svg标签等等。作为一本提供优化思路的册子,我不会在这里把具体的代码提供给你,因为不同版本的工具,总是会有不一样的配置选项。你只要知道,我们可以使用这样的优化手段来达到这样的目的,就可以顺藤摸瓜,找到具有该功能的工具,怕的就是你不知道还能这样处理,也就不会去使用对应的工具了。
# 图片资源优化
前文我们讲过图片的懒加载,那是从加载的角度去讲,现在,我们从图片体积的角度去进行优化。
# 用css绘制图片
其实有些图片是不需要的,比如我们以前喜欢用一个图片作为分割线,但是现在不会再有人这么干了,我们会使用css来绘制出效果差不多的分割线。类似的效果还有圆角、阴影、斜边等等。随着css能力的增强,我们现在可以用css绘制出非常多的效果,例如渐变、散漫、裁切等等。当然,有些css能力需要消耗比较多的计算资源,又会从另外一个角度降低性能,因此我们要避免使用这种属性来替代图片。
# 善用srcset属性
不同显示屏分辨率不同,2倍高清图自然需要更大的体积,因此,我们可以通过srcset来确保在低分率屏下使用1倍图,避免不必要的浪费。
<img src="some.jpg" srcset="some@2x.jpg 2x,some@3x.jpg 3x">
除了img,picture标签也是支持srcset的。
<picture>
<source media="(min-width:800px)" srcset="some@2x.jpg 2x,some@3x.jpg 3x">
<img src="some.jpg" />
</picture>
# 挑选适合的图片格式
图片格式是几乎所有和前端相关的材料都会讲的。我这里就长话短说。
- jpg 压缩率高的同时,还能保证较好的图片质量,但是无法透明
- gif 色域窄,体积大,但支持透明
- png 压缩率最差,体积大,支持透明,但无法像gif一样有动画效果
- webp 体积小,支持透明,压缩率还很好,除了无法支持动画,苹果设备上兼容性差
- svg 矢量图,但是渲染性能最差,涉及比较底层的svg渲染逻辑
jpg的压缩模式有两种,一种是基线模式,一种是渐进模式。基线模式的图加载的时候就像放下来的投影幕布一样,一点点给你看。渐进模式的图则像迷雾中走来的美女,一开始模糊,逐渐清晰起来。如何选择使用哪种图片格式呢?有一张图可以参考:
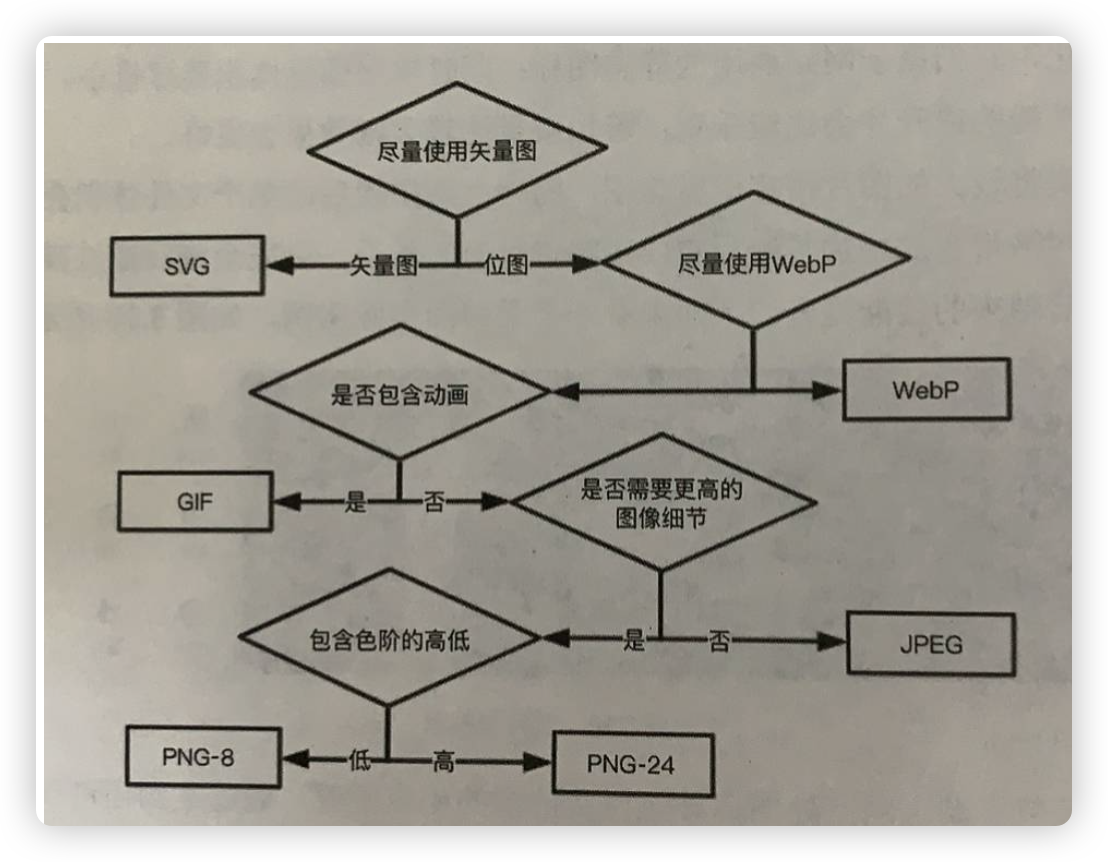
来源 田佳奇《Web前端性能优化》
当然,选择图片格式的前提是,在相同一张图的情况下,但是很显然,比如gif可以动画,svg可以矢量,这种是没有得选的。
# 图片压缩
除了图片格式,我们还可以自己对图片进行压缩,比如某些cdn提供的压缩功能,一张几M的图片经过压缩后只有100多k,而且你揉眼还不大能分辨的出来它们的差异。
如果自己对图片进行压缩呢?又一个imagemin插件可以帮你实现,在你写代码时,拿到一张图片,可以在node环境下用gulp等工具统一对图片进行压缩。当然,如果是在线的图片,就使用cdn好了。
# 尺寸缩放
有些图片存在一些操作上的逻辑,我们都见过百度地图,通过滚动来缩放地图的时候,难道真的是把一张图片进行缩放了吗?不是的,它是按照比例尺,取了对应比例尺下面的新图片进行展示。比如我们应用中有些图片需要点击之后放大查看原图。这些场景下面,我们可以先用小尺寸作为预览图,然后在点击之后,根据当前屏幕的大小再提供对应尺寸的照片。抑或,在通过鼠标缩放图片的时候,根据缩放到的尺寸大小,再去加载对应尺寸的图片来替换当前图片。基于这一方案,我们可以在大部分情况下,使用尺寸较小的图片,从而加快加载速度。
# 使用base64地址
在我们应用中如果存在一些尺寸比较小的图片,可以讲该图片转化为base64的字符串来直接使用,从而把图片转化为代码形式,就无需避免请求加载了。
<img src="data:image/jpg;base64,/9j/4QMZRXhpZgAASUkqAAgAAAAL....">
或者在css中作为背景
background-image: url("data:image/jpg;base64,/9j/4QMZRXhpZgAASUkqAAgAAAAL....")
虽然我们可以在对图片进行压缩之后再base64,但是它仅适合哪种尺寸很小的碎碎图,而不适合稍大尺寸的图,我们常用的照片也不适合。这是因为base64地址形式会大大增加我们宿主的代码量,反而降低宿主文件的加载速度。当你把文件转化为base64之后,如果超过两行代码,就应该止损不用。
# 使用视频替换gif图
对于简单、尺寸小、动画时长短暂的gif,使用时没有什么问题。但是当gif图尺寸大、帧数多、色彩复杂,则会遇到非常大的加载和解码性能损耗,而且由于解码会占用资源,还会阻塞渲染。相比之下,将gif转换为mpeg-4或webm格式的视频来替代,可能是一个更好的选择,虽然听上去视频好像会更耗性能,但是在替代体积很大gif,不仅在体积上大大缩小,而且播放质量上也有比较大的提升。
# Sprite雪碧图
我们老一代的前端程序员必备的一项技能,就是把我们的icon图片集合到一张图片中,通过background-position来控制需要展示的位置,从而实现图标。为什么要把一些碎碎图合并为一张图呢?因为我们都知道图片的加载是损耗性能的,从网络传输和图片加载的角度都会让这个小图片在一开始不出来,一片白色,等到传输加载完之后才突然出现。举个场景的例子,我们希望用户鼠标放到某个位置的时候,图标从向上箭头变为向下箭头,但是由于我们用一张小图片进行替换,这就会导致用户第一次把鼠标放到上面时,箭头消失了,等了一下之后才突然出现新箭头。而如果把这些碎碎图合并到一张图片内,通过background-position来展示想要的某个区域,就可以用加载一张图的消耗一次性加载所有需要的图标。
由于这项技术都是依赖css background-position,所以它的使用条件有限。一些插件,在构建过程中,自动把background url替换为雪碧图,并自动加入background-position。
# 字体资源优化
其实字体资源没有太多的建议,主要有两点:
- 裁掉不需要的字,把包做到最小,需要加字的时候再加进去
- 预加载字体文件
字体格式虽然和图片格式一样,有大小区别,但是不同的浏览器支持的字体格式又不一样,导致我们无法只使用一种格式,所以大部分还会把所有格式都放一个在项目里面,通过font-face来使用。
# 压缩上传
我们提交表单也好,文件也好,上传速度也受到提交内容的体积影响。首先想到的是压缩,如果我们想要实现压缩,就必须前后端一起做,而且由于算法需要引擎,不同情况下压缩效率还不一样,相同的算法有的压缩率能到惊人的50%,有的则只有可怜的90%,有的甚至比原始数据还大,气死人。我们要掌握不同压缩算法的规律。
普通字符串,或者JSON数据转化为字符串,可以使用LZ算法进行压缩,LZ算法是目前主流的压缩率最高的字符串压缩算法。前端可以通过lz-string等库进行压缩提交,后端可以使用LZ算法解压工具对提交的数据进行解压。
图片则可以使用canvas转化为base64字符串后再进行LZ算法压缩上传。当然,已经有库实现了这个过程,在github上搜索js image compression就能找到需要的资源。当然,除了走字符串压缩之外,还可以走图片本身的压缩路径,通过读取图片转化为arraybuffer之后,利用色域色相等原理,降低图片的质量和尺寸,处理完之后再从arraybuffer转化为blob在实例化为File对象进行提交。
# 分片上传
对于比较大的文件、图片,可以采取分片上传的技术方案。单个文件比较大,上传的耗时就比较长。我们把一个文件拆分为多个小chunk,一起并行上传,利用浏览器可以同时发出多条请求的特点,减少上传的总体时间。分片上传的技术要点就是要建立一个索引,能够让服务端知道这些小块之间的链接顺序,在接收到所有小块之后,按照这个索引又把它们组合在一起复原为一个完整的文件。在技术上,我们可以将文件转化为arraybuffer,在进行切片和索引建立,再以流的形式直接上传buffer,当然,我们需要手动操作arraybuffer在分片开头64位用来记录索引。另外,分片上传还要有一定的冗余和重试,否则一旦某一个小块上传失败,就无法复原整个文件,反而得不偿失。
# M3U8视频格式
我们都知道视频一般都比较大,有些网页打开自动播放一个视频,做出非常不错的效果,但是苦于视频要加载很长的时间,这种效果的惊喜被降低了。但是其实MP4是支持流式加载的,也就是一边播放一边加载,当然,如果在中途播放完了还没有加载出新的chunk,就会卡顿,不过如果能够尽快开始播放也是不错的,这就需要对视频做更细微的处理,在视频头中给出更多信息,才能帮助视频播放器正确解码。
而M3U8格式则是像分片上传一样,对视频进行分片播放,M3U8格式的视频文件本身并不存储视频的内容,而是一个文本文件,用于索引一个视频从第几分钟到第几分钟到块对应的地址。当播放器播放M3U8格式文件时,它首先读取一些元数据信息,然后就直接下载第一段视频进行播放,被下载的视频段一般是.ts后缀的视频块(有些播放器甚至可以单独播放一个.ts文件),由于M3U8中提供了更多信息,当这个块被播放完之后,就会去读取下一个.ts文件来进行播放。这样当用户在看到一半退出时,没有播放到的视频块就不会被请求。切分为块之后,视频加载的速度也大大提升。当然,我们前端自己其实也是可以去做视频解码器的,我们可以在原有的视频解码器基础上封装一些能力,比如我们可以封装为一次加载3段,播放器播放到第2段的时候就去下载下一批,这样可以保证有足够的时间去重试可能请求的错误,保证播放的连续性。
# 网络优化
做前端,网络知识不可或缺,而在性能优化领域,对网络的优化也是重要一环。接下来,我们将对网络优化的三大招(CDN、缓存、http2)进行介绍。
# 网络请求优化
让我们回到那个“当你在浏览器中输入url之后……”的面试题。我们需要确定一点,浏览器首先是一个网络请求器,然后才是一个渲染器。当浏览器准备开始按照你想要的开始工作的时候,首先它会拿着域名,去DNS服务器查询这个域名对应的是哪台服务器,这服务器的IP地址是啥。我们知道,IP是一台服务器的门牌号。拿到IP之后,还没法获得服务,得想办法从服务端拿资源。怎么办?我们用http协议来实现呀。不过不好意思,想要http,还得先TCP,http是基于TCP的协议,所以得先基于IP进行TCP连接(说到这里,前面DNS解析不也是为了拿IP嘛),三次握手。TCP连接好了,接下来就是http请求啦。
这里有3个步骤:DNS,TCP,HTTP。所以,每一步都有优化空间。首先是DNS,额,怎么说呢?通用域名是没有机会优化了,但是特殊环境下又可以优化,比如公司内统一网络出口的情况下,公司自建DNS,从而可以更快的获得IP。而TCP也没有什么优化空间,当然,如果是自建客户端,就有机会,比如用UDP取代TCP。
HTTP层面,我们可以和后端、运维同学一起,做一些优化。
- 避免重定向
- 减小cookie体积
- Gzip压缩
- 缓存(下一节讲)
- HTTP2(下下下节讲)
当然,实际上,这些网络层面的优化,其实前提是访问者的宽带。假如别人是100G光纤,和另一个是256k的电话线,那能一样嘛。
# HTTP缓存
在前面提到的文章一样,HTTP缓存有三种模式。
- Cache-Control + Expires
- 304 + Last-Modified
- 304 + Etag
另外,我们还能把这三种中的两种混用在一起,起到更可控的缓存。
实现HTTP缓存也得后端来做,一种是对静态资源,可以通过配置nginx或apache配置中做到,还有一种是通过后端程序来做,特别是Etag,只能通过后端程序按一定算法来实现。
# CDN
前面我们讲到我们没法优化DNS,但是有些人却可以,那就是DNS服务商。我们把域名托管给他们,他们就可以根据用户访问的情况来把域名解析到不同的地方,比如你有一台服务器就在用户所在的城市,那么就让DNS服务商(或者自建的DNS服务器)把这个用户解析到这台服务器,那么此时建立TCP也好,网络传输也好,都会快很多。CDN就是基于这样的想法,把我的资源和数据存到离用户更近的服务器上面,这样通过DNS解析,就能让用户访问离自己最近的服务,提供最近的资源,建立从数据库提供最近的数据资源。至于数据的写,就没有办法,只能往统一的数据库去写,不过我们可以在架构上进行设计,比如设计多层阶梯的写逻辑,或者在主备服务器之间拉一条100T的超大光纤。总而言之,通过使用CDN服务,我们让我们的用户可以更快下载应用资源和数据。
# HTTP2
HTTP/2 是相对于其前身 HTTP/1.x(尤其是 HTTP/1.1)的一个重大升级,它在性能优化、安全性和效率方面引入了许多改进。HTTP/2 的主要优势包括:
- 二进制协议:HTTP/2 使用二进制而非文本格式进行数据传输,这使得解析更高效、更少出错,且更紧凑。
- 多路复用(Multiplexing):在同一TCP连接中并行传输多个请求和响应,减少了因多个HTTP传输导致的延迟。这解决了HTTP/1.x中的“队头阻塞”问题,即之前版本中一个请求的处理会阻塞后续请求。
- 头部压缩:HTTP/2 引入了专门的算法(如 HPACK)压缩请求和响应的头部。由于头部在每个请求中几乎都是重复的,这种压缩可以显著减少需要传输的数据量。
- 服务器推送(Server Push):服务器可以主动向客户端推送资源,而不需要客户端明确请求,这可以进一步减少加载页面所需的往返次数和时间。
- 流优先级(Stream Prioritization):允许客户端指示哪些资源是更优先的,这样服务器可以先发送最重要的数据,确保最关键的资源最先加载完毕。
- 更强的安全性:虽然HTTP/2 协议本身并不要求使用HTTPS,但几乎所有的浏览器实现都要求通过安全的TLS连接来使用HTTP/2,这提高了网站的安全性。
- 减少了TCP连接的数量:由于多路复用,对同一个服务器的所有通信都可以通过单一的连接进行,这减少了创建多个TCP连接的开销和复杂性。
当然,http2建立在https基础上,所以实际上,单次连接其实性能有所损耗,但是从整体规划看,它具备更高效的传输机制,比如它通过二进制分帧传输,没有前文所讲的并行请求数量的限制,那么也就可以不再依赖webpack之类的打包工具了,一次性直接下拉100个体积更小的文件,可以更快。另外,以前我们有keep-alive,但是http2更厉害,还可以实现server push。
不过http2仍然依赖于TCP,所以最后的性能瓶颈都在TCP上去了。简单来说,三次握手四次挥手还是少不了,而且http2虽然可以传输更多的文件,但是每次文件的大小要求不能太大,不然还是很容易造成白屏现象
# WebSocket/WebRTC
除了http,我们还有其他武器,它们都可以从其他侧面解决我们使用http过程中遇到的一些性能损耗的问题。WebSocket可以做到服务端向客户端推送消息,建立持续性的连接,这样我们就不需要每次都通过http去请求数据,而是可以让服务器直接推送给我们,省去了中间各种网络连接,而且还能无感更新界面。WebRTC可以做到客户端之间直接通信,比如你的应用需要在用户之间交互数据,就可以使用webrtc,不需要经过服务器。
# 应用分发机制优化
通过对应用架构的重新设计,我们可以从分发机制的角度去优化应用的加载速度,提升其打开的速率,从而提高用户体验。什么事应用分发呢?就是客户端以何种形式启动应用,基于这种形式,需要我们怎么安排代码的部署、下载和调用。
# PWA
渐进式web应用(Progressive Web Apps)是一套技术的集合,而不是指单一技术。简单讲,PWA通过各类缓存机制和控制机制,将应用加载时需要的资源缓存在本地,从而让下一次加载该资源直接从本地加载,进而提升性能。除了性能,它还提供窗口优化、通知推送等其他方面的能力,提升用户体验。不过就我个人而言,并不看好PWA,因为我们大部分应用都是需要从服务端拉取数据才能使用的,而且PWA并没有提供超出浏览器能力的功能,比如读取本地文件系统的能力等等,所以在国内我很少见到专门的PWA应用,不过也有不少应用使用了PWA部分能力,来提升应用的加载性能。性能方面主要涉及ServiceWorker的内容。
# ServiceWorker
ServiceWorker是一种特殊的WebWorker,从线程工作的模式看,和WebWorker是一致的,但是不同的地方在于,它是全局只会有一条ServiceWorker线程,而且ServiceWorker中提供了比普通webworker更多的接口,以实现特殊的能力。其中一项重要的能力,就是缓存资源。
在serviceworker中,提供了caches接口,通过该接口可以实现缓存的读取、写入、删除。再利用serviceworker中拦截请求的能力,当当前应用去请求某一个资源时,会被serviceworker拦截,我们可以在worker脚本中监听fetch事件,通过缓存的判断,直接respondWith缓存内容,而不需要再往服务器发送请求拉取资源。
不过ServiceWorker有一点,即它需要一个注册的过程,也就是用户第一次打开应用的时候,我们只能做到注册,而注册之后serviceworker内的逻辑并不能马上生效,只有我们重新打开应用(或刷新浏览器)后,才能享受其提供的服务。
利用serviceworker,我们还能做很多事情,它不单单可以缓存,还可以实现常驻后台拉取,这样的话,我们就可以在后台自己去更新一些资源,或者提取拉取一些资源,从而做到让用户在无感的情况下,获得应用的加速。
# Workbox
Workbox是谷歌基于自己的场景封装的ServiceWorker库,它提供了我们常见的一些场景下,快速实现serviceworker中某些能力的方法,就像jquery精简了DOM的操作一样,workbox也是精简了我们使用serviceworker的操作。
# 微前端
这两年微前端度过了巅峰,今年开始微前端就不那么热了。但是,微前端到底是怎么回事呢?对于刚接触的同学,我还是有必要简单介绍一下。
通过微前端,我们可以做到类似按需加载的效果,从而提升应用的加载性能。微前端由基座应用和子应用构成,应用打开时,需要首先加载基座应用,当然,我们会同时并行的根据路由去加载对应的子应用。不同的应用同屏的子应用数量不同,如果一屏只有一个子应用,那么只有当切换路由,需要加载另外一个子应用时,才会去加载新的代码。当然,我们也可以做一些预加载的工作。
不同的微前端框架实现模式不同,知名框架qiankun基于沙箱模式加载子应用,实际上会严重降低子应用运行时的性能,并不适合需要大规模计算和交互的应用,只适合一些不复杂交互不频繁的应用。但是另外还有一些微前端架构,并不依赖沙箱,不过一般会统一技术栈,比如基于angular或react的微前端框架,就要求子应用必须是对应技术栈的,但是这类微前端框架的运行性能就好很多,和普通的单体应用差别不大,所以也可以用来运行有计算,且交互复杂的应用。
微前端作为前端的一种架构方式,已经改变了前端项目代码组织的方式。在前端性能方面,基于微前端架构,以及强制性做到了按需加载,子应用分包。对于前端项目而言,很多项目到最后都会考虑采用微前端架构,但是由于架构变化带来的破坏性非常大,所以一些已经持续了几年的巨无霸应用想转微前端,就异常艰难。所以,我建议当一个项目运行了1年左右,负责人发现未来该项目还会持续迭代时,就应该赶紧考虑采用微前端架构进行重构。这样就可以避免应用打包变大后加载更慢,也可以将庞大的应用分开治理,从而做到更优秀的代码治理。
# 浏览器渲染原理
# 浏览器渲染流程
让我们接着回答“当你在浏览器中输入一个url……”的面试题。完成网络请求、资源加载之后,浏览器就进入到了渲染阶段。在加载资源结束时,浏览器会解析html, css, js,产生DOM和CSSOM,其中js会在加载时立即执行,js的执行过程可能对已有的DOM和CSSOM进行修改,但当这些加载过程完成形成稳定态之后,浏览器就正式进入渲染阶段。
它首先会基于DOM和CSSOM构建渲染树/帧树。所谓渲染树(Redner树),你可以理解为一个数据结构,一个多叉树,每个节点包含对应的元素和样式信息,遍历渲染树就可以得到整个界面所有渲染信息。在得到渲染树的过程中,浏览器会根据渲染树实时的进行布局(Layout),用以在其内部计算好屏幕上的每一个点位应该显示什么内容,确定每个节点在页面中的确切大小位置等。由于这个过程是实时的,所以构建渲染树本身就是一个挺好性能的事儿。布局时它会基于“盒模型”精确的捕获每个元素在窗口内的确切位置和尺寸,转化为屏幕上的绝对像素。
浏览器就能根据渲染树进行绘制(Paint),绘制就是按照布局时计算的所有详细信息传给绘制引起,在屏幕上,一个像素一个像素的进行显示,这个过程也被称为“光栅化”。绘制的过程中,绘制可以将布局树中的元素分解为多个层。浏览器还可能采取一些分层绘制的策略,有些绘制会转移到GPU中进行计算,而不是在CPU中,例如, 以及opactiy和3d transform等 (opens new window)。由于CPU承担了大量系统级、应用级、程序级的计算,如果能够让闲置的GPU参与绘制计算,就可以大大提升性能。但是由于GPU和CPU计算由不同线程来做,所以又必须考虑到线程间交互所带来的性能损耗,所以,并不是任何情况下开启GPU计算都更快,这在下文讲GPU部分再详细阐述。总之,Paint的结果,就是浏览器显示在屏幕上的依据。
当文档的各个部分以不同的层绘制,相互重叠时,必须进行合成,以确保它们以正确的顺序绘制到屏幕上,并正确显示内容。
以上是浏览器加载完应用到你能看见界面的过程。
在应用运行过程中,我们通过js,或者css,通过用户的某些操作,可能会改变应用界面的呈现。比如基于js的轮播图,比如基于css的鼠标hover效果等等。随着资源的继续加载、用户的操作,以及代码层面,我们可以能重新操作DOM,修改DOM元素的样式等等,这些动作中的部分内容会引起浏览器重新创建Render树、重新绘制,这也就是reflow(重排/回流)和repaint(重绘)。
但凡出现了上述情况,repaint就一定会发生,说白了就是屏幕得重新刷新一下,不然你怎么看到界面上的变化呢。但是reflow是可选的,因为有些操作并不会引起布局的变化,比如某个元素只是颜色发生了变化,那么就不会发生布局变化,也就不会有reflow。
一般来说,reflow和repaint是无时无刻不在发生着的,只是这个过程是不是需要比较大的计算量。相对来说reflow更消耗性能,因为repaint更接近系统底层,几乎是按照相同的逻辑执行的,但是reflow则每次都要进行非常复杂的多叉树遍历,而且在短时间里面可能会多次触发重新计算,所以比较消耗性能。浏览器按照16.67ms/帧的速率刷新绘制的内容,如果在这16.67ms内,reflow和repaint没有计算完,那就得等到下一个16.67ms才能进行新内容的显示。也就是卡顿。
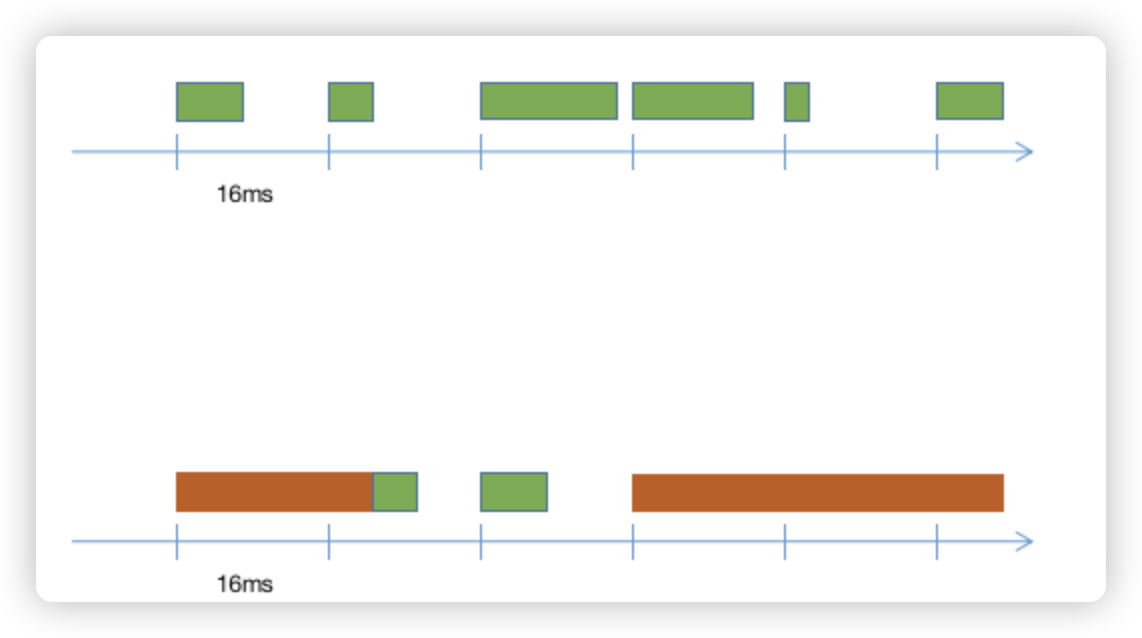
上图中横轴是时间轴,每16.67ms浏览器就会执行一次渲染动作,但是前提是浏览器执行任务已经结束,交给了浏览器进程,如果JS引擎中还有任务在执行,就会导致没有把执行权交还给浏览器,浏览器就认为当前界面不需要刷新,上图中红色的块代表长任务,一个任务的执行时长超过了浏览器刷新一帧需要的时间,就会导致浏览器不会在该刷新的时候使用新的渲染树进行渲染,直到长任务执行完毕,在下一个刷新周期,浏览器才会一次性按照最新的渲染树进行渲染,这就导致在之前的刷新周期内原本应该展示新内容而没有展示,界面出现了瞬间比较大的变化,也就出现了卡顿现象。
现在,我们可以完整的回答上面的面试题了。我用一张图来表达:
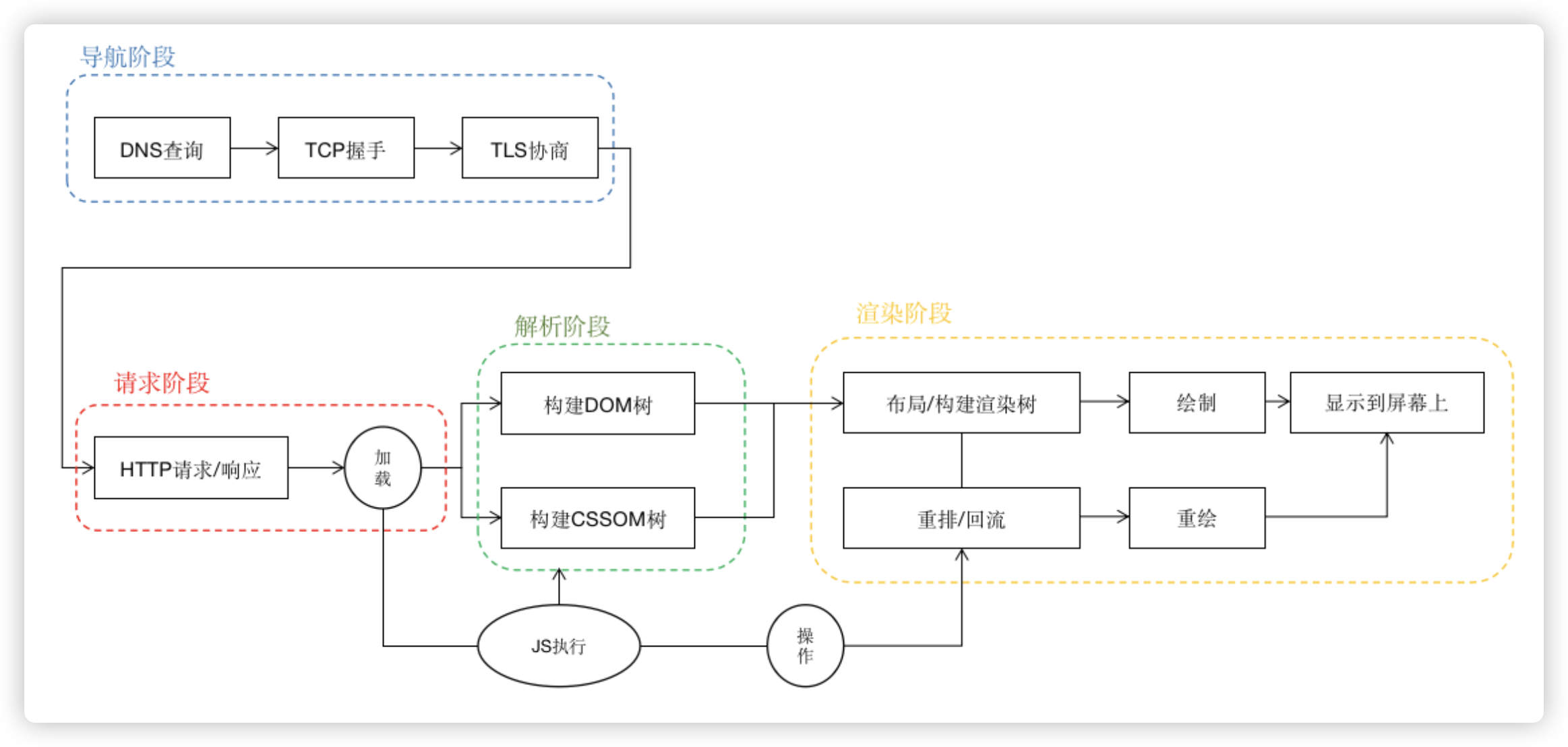
上图没有表达出来的是,如果我们的应用按照按需加载的方式加载模块或子应用,那么还会有一些链路,但是我们统一把这些链路隐藏在上面的最底下,即“导航->请求加载->JS执行-操作DOM或CSSOM->重排->重绘->显示”这样的一个链路。不过因为没有解析阶段,其实和我们完整的链路而言没有必要去深究。
# 浏览器线程详解
首先咱们不免俗的介绍一下“进程”和“线程”的区别。
“进程”(Process)是系统资源分配最小单位,浏览器打开之后会有多个进程,包括:
- Browser进程:也就是浏览器作为一个客户端应用程序的进程,可以理解为浏览器窗口的进程,比如浏览器的历史记录、代理等功能,都属于浏览器层面的功能
- 第三方插件进程
- GPU进程:调用GPU的进程,无论打开多少个tab,只会有一个,用于和GPU调用、通信
- 浏览器渲染进程:浏览器实现作为浏览器价值的核心进程,加载、渲染、解析,一般来讲,每一个tab会启用一个新渲染进程,所以一个tab挂掉,不会影响其他tab,也是最消耗资源的进程
“线程”(Thread)是CPU的执行某个任务的基本单位,也就是要执行某种特定特性的任务,我们就开一个线程,专门做这类事。一个进程里面可以有多个线程(当然也可以只有一个),进程为多个线程提供了统一的一些东西,例如内存、其他一些资源等。也就是说,单个线程挂掉,很可能影响整个进程的正常工作,甚至让进程挂掉。对于浏览器来讲,我们主要关注浏览器渲染进程里面的线程,主要包括:
- GUI线程:负责渲染界面,所以也叫“渲染线程”
- JS引擎线程:负责解析和执行js,例如把v8引擎拿过来倒腾一下开出一个线程,因为被我们经常使用,所以也被称为“主线程”
- 事件触发线程:用来处理各类事件,比如用户的点击、鼠标移动等等
- 定时触发器线程:用来处理定时触发器,例如setTimeout, setInterval的调用函数,什么时候执行呢?靠本线程
- 异步http请求线程:用来处理http请求的线程
- 其他线程:serviceworker和我们自己new Worker起来的线程,webassembly的执行线程等等
其中,JS引擎线程和GUI线程是最重要的线程,其中JS引擎线程在我们前端编程中起到最重要的作用,所以才被称为“主线程”。JS引擎线程和GUI线程都只能有一个,也就是单线程。单线程意味着要执行下一个任务,得等到上一个任务执行才能执行。
不过,比较惨的是,JS引擎承接了所有JS的执行,事件触发了,把回调函数丢到JS引擎执行,定时器到点了丢到JS引擎执行,http请求结束了丢到JS引擎执行,太累了。这也就是为什么JS慢的原因。(这里插一句,JS的执行有浏览器的事件循环机制,即Event Loop,这个事件循环机制不是单个线程的事,是浏览器应用层面的设计和调度,而其中调度的过程就是在这些线程之间进行协调。)
JS还可能操作DOM和CSSOM,修改完之后,GUI线程拿着渲染树去渲染,所以也是比较辛苦。
正是因为JS引擎线程和GUI线程做牛做马,完成着所有任务的最终运行和渲染,所以才让我们的界面老是卡!卡!卡!那怎么办呢?当然是需要我们有非常清晰的大脑,让它们不要那么累。减少程序运行过程中的任务堆积,通过时间切片等策略,让长任务不那么长,后面还会介绍worker线程,worker线程有自己独立的JS引擎,所以不会占用主线程的资源,可以和主线程并行运行,比如一些计算,丢给worker线程去算,算完之后再丢回给主线程,这样主线程就不用那么累,把省下来的精力用来执行一些其他的渲染逻辑,也就不用那么卡了。
# 页面结构优化
页面是由代码构成的,渲染是基于渲染树而来,在我们构造页面时,其结构对渲染的顺序、效果,都有影响。通过优化页面结构,有利于渲染引擎更快的渲染出我们需要看到的内容(不是渲染更少内容),从而提升用户体验。
# HTML结构优化
浏览器首先基于HTML结构解析出DOM树,然后在过程中会执行JS代码,DOM树可能被修改,但基于HTML的DOM树是基础,包括我们通过JS产生的DOM结构,在渲染时都应该注意,把需要尽快展示的内容放在页面的前面。我们来举个例子:
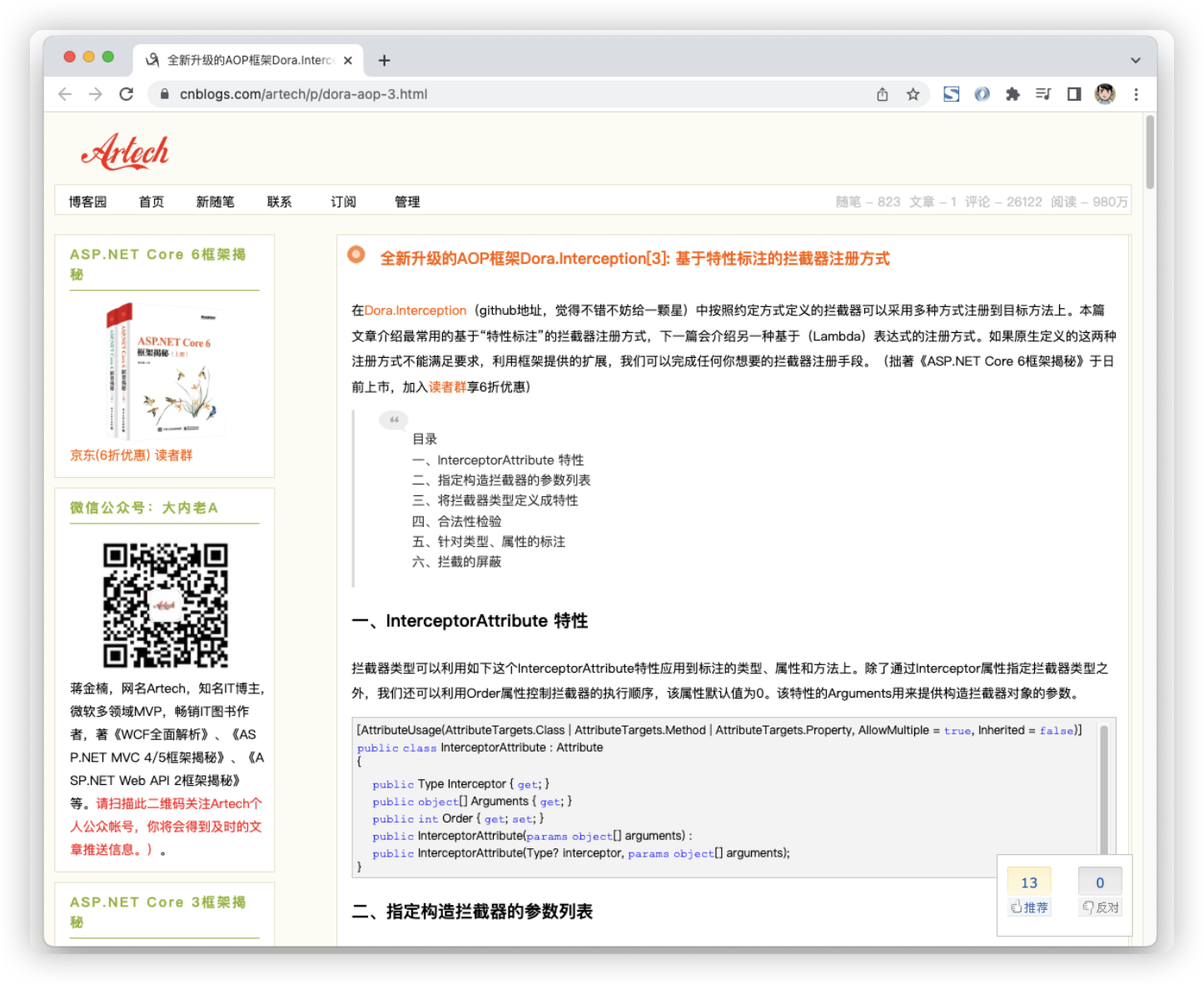
上图是一位博主博客的截图,博客分左右两栏,右边为主内容区,我们希望读者更先看到右边的内容,但是它左边栏的高度也特别高,如果按照我们正常的思路,左边的html写在前面,那么就可能由于加载慢,导致内容很长时间加载不出来,但是,我们把右侧主内容区域的html写在前面,左边写在后面,那么在加载时就可以更快加载出内容区域。但是这个过程中我们必须注意一点,当左侧边栏还没有加载时,我们需要让右边靠右,而不是等左边出来之后,再被顶到右边去。
虽然HTML中的很多细节都可能影响性能,但是我们应该尝试养成良好的习惯,有些问题不可避免,但是在大部分情况下,这些问题并不会引起性能损耗,所以只要我们按照一定的习惯来撰写HTML结构,就可以规避大部分问题。我总结出以下你应该养成的习惯:
- 使用HTML5,而非HTML4及其以前的版本
- 使用语义化标签,而非全部都是div
- 按照内容的重要性安排内容块出现的顺序,但是不能过度优化,例如你不能直接把
放在 - 能用HTML处理的,不用JS处理
- 能用CSS处理的,不多加一个div来作为工具
- HTML属性中的data-, aria-属性应该被广泛使用
- 减少HTML的层级
- 在JS中适当移除不需要的节点,较小的DOM树可以获得更快的渲染过程
- 对HTML进行压缩
但寄希望于通过优化HTML结构能够获得飞速的提升,并不现实,但能够有更好的细节表现,比如先加载重要部分、交互的时候更流畅的展示内容,就已经达到我们优化性能的目标了。
# SVG渲染原理与优化
SVG作为类似方案的最终胜出者,具有自己的优势,它实现了DOM接口,比Canvas方便的多,比如通过监听某个节点就可以做到SVG节点的交互,而Canvas要实现该功能,却要做大量计算才能做到。而且,我们可以直接在SVG中使用css,利用css做到动画效果,替代部分gif的功能。但是SVG的一个大缺点,就是加载、渲染慢。加载慢主要是指解析的过程慢。对于SVG的使用,我总结了自己的一些优化建议:
- 内联inline会比直接使用img[src]引用消耗更多的性能,因为需要在当前DOM树中建立SVG的DOM子树,因此如果仅仅是展示图片,而无需进行交互,最好使用img[src]
- 使用基本图形,如方形、圆形、直线等,而非用path来画这些图形
- 在构建时,清除svg中用于注解的部分
- 对svg代码进行压缩
由于SVG的渲染是独立的,以viewbox为渲染视口,而同时,它又要兼顾DOM的生成,因此性能比较差。自己构造svg时,应该尽可能避免把不展示在视口中的内容也生成到svg代码中。另外也可以在外部使用css来控制svg内部的元素,在svg内使用css需要svg渲染引擎一并工作,而在外部使用css则同一走浏览器渲染引擎,可以节省渲染消耗的性能。
# 浏览器渲染优化
前文,我们已经掌握比较多浏览器的渲染原理了,现在我们来尝试找出一些技巧,优化浏览器的渲染效率,避免出现卡顿现象。其实,我们无法调节浏览器的渲染能力,除非我们加大自己电脑的硬件投入。我们能做的,主要是去避免一些常见的劣质代码,避免由于这些代码导致浏览器渲染过程中有较长的执行任务,从而导致渲染卡顿。
# 避免引起不必要的重新渲染
我们知道,重新渲染会消耗性能,但是怎样的重新渲染会比较耗性能呢?我总结了如下情况:
- DOM树的变更引起的reflow+repaint
- 样式变化引起的reflow+repaint
- 需要跨线程处理的渲染过程,例如复杂的GPU渲染
- 需要跨引擎处理的渲染过程,例如svg的变化
可以看到,最常见的问题是我们的某些操作引起了reflow。实际上repaint的效率其实还是比较高的,一般不会有性能问题,因为paint的本质就是遍历渲染树,然后光栅化。而reflow的本质是重新计算要在屏幕中展示的内容的尺寸、位置等,虽然在paint的时候只需要绘制视口范围内的内容,但是如果不完整计算整个渲染树,浏览器也不知道哪些内容要在视口渲染,所以这个计算过程是非常耗性能的,即使你的界面上只有一根头发丝的位置移动,它也需要去计算整个渲染树,因为它也不知道这一根头发丝的变化是横向的纵向的,只有计算完它才知道原来只是一个细微的变化,可是这个时候已经计算完了,性能已经损耗掉了。
那哪些是会引起reflow的操作呢?你只要记住,但凡会引起尺寸、位置变化的,都会引起reflow。(当然,会有例外。)比如你加入了新的DOM节点,虽然它display:none是隐藏的,但是浏览器不计算怎么知道它不需要显示呢?比如你通过style.marginTop进行了样式调整。
那么哪些操作是不会引起reflow,只会repaint呢?比如纯粹的颜色变化,例如style.color操作。另外,translate所带来的偏移也不会引起reflow,这个就是前面说的“例外”,它会调用GPU来计算对应元素应该放到哪个位置,并且使用新图层来渲染当前节点(新图层在前面讲布局Layout的时候提到了一下,没有深入),使得这个节点的渲染具有复合(compose)性质,基于和原始DOM不同的渲染逻辑,新图层会基于GPU来计算和独立渲染,所以不影响原始布局,因此也不会引起reflow。当然,其实使用translate也好,其他的transform属性也好,前提是你的电脑GPU的调用比较流畅,如果电脑本身的软硬件环境让浏览器使用GPU加速时更慢,那么使用GPU加速反而会降低界面渲染的性能。当然,还要考虑电脑这些就太细了...可以无视...
# 节流防抖
这是常见的避免卡顿的技术。节流是按照一定的时间周期执行调用,在单一周期中,调用只会被执行一次。防抖是按照一定的时间延迟调用,如果在时间内再次调用,那么前一次调用将会被弃用,只有最后一次调用会被执行。之所以存在这样的技术,是因为我们常常反复的进行某些操作,这些操作引起reflow,就会导致长任务的存在,引起卡顿。而通过这两项技术,就可以让这种反复进行的操作在短期内只执行一次,这样就可以让reflow过程中执行更少的动作,从而避免卡顿。
此外,防抖还常常用在一些要发出ajax请求的场景,因为向服务端发起请求是比较慢的操作,而且网络请求异步特性,我们不知道请求什么时候回来。所以这种情况下使用防抖技术,可以保障我们只请求一次,而且是最后一次。比如在某些输入关键字进行请求的时候。但是有的时候,如果我们持续输入,导致请求无限延迟,又很不合理,此时我们要把节流和防抖结合起来,在防抖的同时,又能按一定周期发出ajax请求。
当然,节流防抖不是万能的,有些情况下我们使用节流防抖会导致业务逻辑执行错误,在这种时候,我认为只要没有严重的卡顿,就不要使用。
# 虚拟视口技术
我们经常遇到一些长列表、大表格的场景,而如果你有所接触,都会阅读到一些被称为“虚拟列表”“虚拟表格”等解决方案。这些方案统称为“虚拟视口技术”。
我们知道,对于用户而言,他不关心你这个列表或表格全部长什么样,他只关心出现在浏览器屏幕中的这个可视区域的内容,这个可视区域就是我们讲的“视口”,我们开发者遇到的问题就是,当列表或表格的行数非常多时,产生了非常大的DOM树,每一次滚动都会导致reflow,从而导致很慢的重新渲染。解决的方案,就是,我们减少DOM节点的数量,把那些不需要展示在视口内的DOM节点移除掉,把那些需要展示的DOM节点动态的加入到DOM树中。虽然看上去我们在不断的修改DOM树,听上去很耗性能,然而相比于一棵巨大的DOM树的遍历和计算而言,修改DOM树的操作虽然也耗性能,却相对而言更节省。
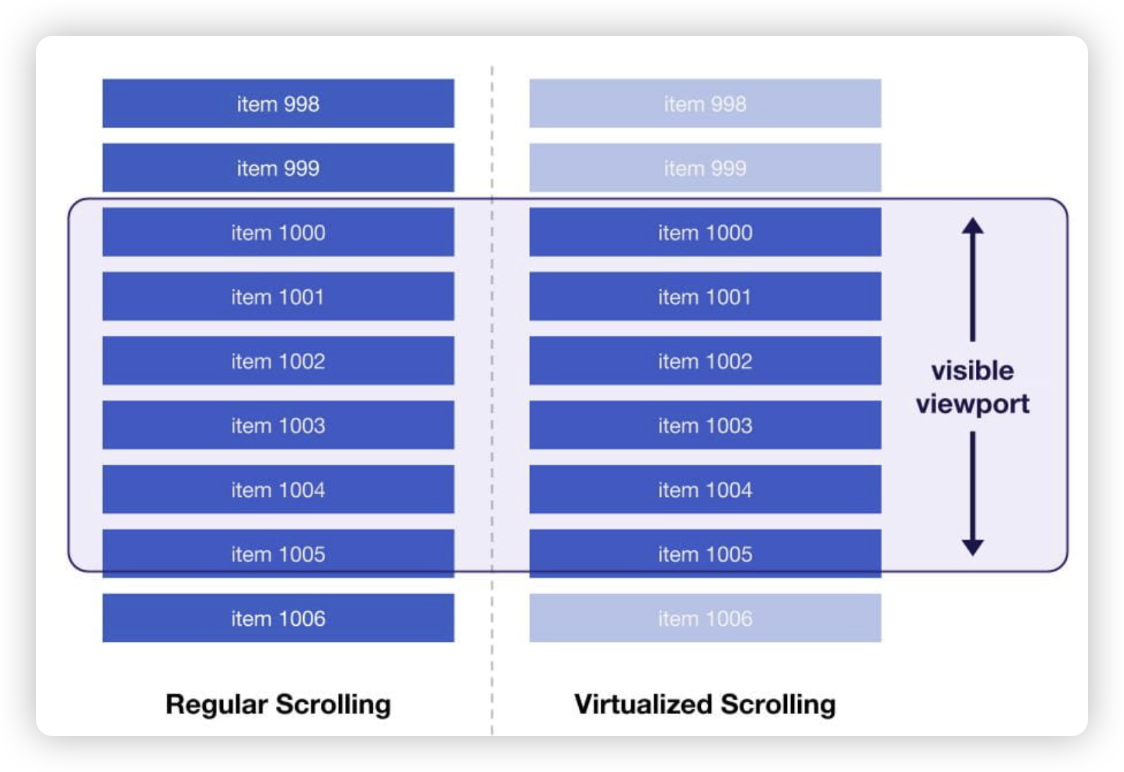
普通滚动和虚拟滚动
基于这一思路,我们可以对列表或表格进行初始的计算,通过滚动条的位置算出当前视口应该展示哪些条目。当滚动条发生变化的时候,把这些算出来的条目构建新的DOM插入到原来视口内的DOM树中,再把不需要展示的部分移除掉。而且为了优化用户体验,我们可以算出比视口内应该展示条目数量稍微多一些的条目,它们虽然不会展示在视口内,但是当用户缓慢滚动滚动条时,可以不需要再去创建DOM,而是直接显示出来,当然在这个过程中,会有新的DOM被创建并插入到列表中,不过由于这些新的节点并不在视口内,所以你也看不到,因此最后给人的感受就是似乎这些条目从来都在界面上,没有被移除过。为了应对用户非常快的滚动滚动条,我们还可以做一些效果,给用户数据在刷刷飞的感觉,实际上可能只是一个装模作样的骨架屏而已。另外,滚动条的位置实际上也不需要那么精确,没有必要动态的去计算滚动条必须在哪个位置,实际上对于用户而言,你只要让他上下滚动的时候能够大致定位就可以了。
# requestIdleCallback
React16开始探索了一种时间切片机制,取了一个流行的名字fiber。其灵感来源于浏览器提供的新接口requestIdleCallback。Idle在浏览器中大意是“空闲时长”的意思,如下图:
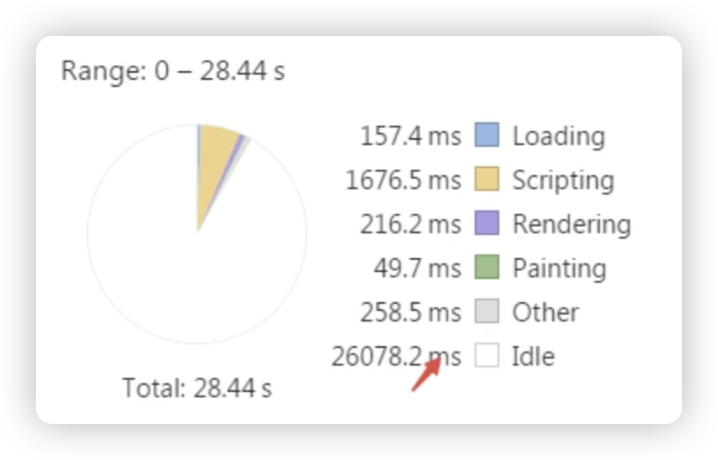
在Performance统计面板中你可以看到Idle这一项。什么是“空闲”呢,就是在前文提到的16.67ms内,执行完任务后剩下的那段时间,如下图:
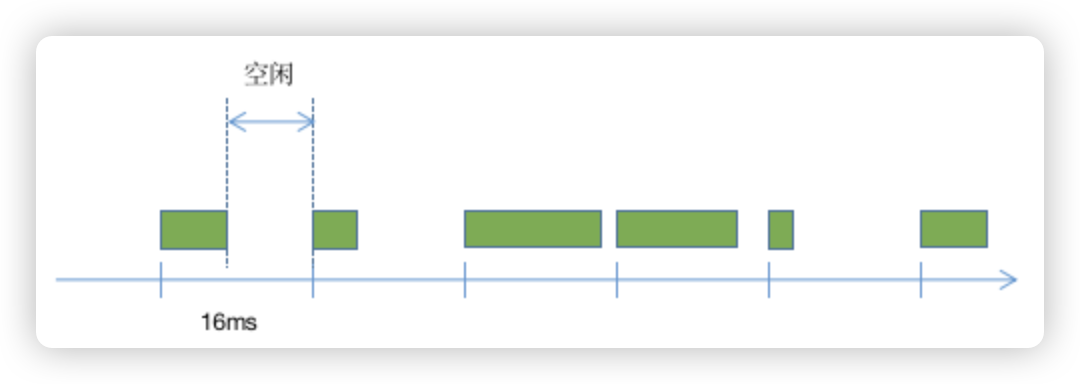
也就意味着,很有可能每一个刷新周期都会存在空闲时长。但是,也有一些情况下,不存在空闲时长,比如前文图片中红色块超越了一个16.67ms的间隔。那么,我们能否把这些超越了16.67ms的长任务进行拆分,把长任务拆成一段一段的短任务,同时把一些优先级比较低的任务放到空闲时长中去执行呢?只要功夫深,长任务变短任务,短任务变不消化渲染的空闲任务。
有些任务与渲染没有任何关系,比如我们会在前端上报日志,但是上报日志前会对日志进行处理。而这个处理过程如果在主线任务中,就会加长主线任务的执行时间,可能就会阻塞渲染。那么我们能否把日志处理任务放到空闲时长中去呢?使用requestIdleCallback就可以,比如下面这段代码:
a()
requestIdleCallback(() => {
b()
})
那么,在执行完a()之后,浏览器就会把JS引擎的任务结束,把控制权交还给浏览器,浏览器就会调用GUI线程开始渲染,等渲染结束后,发现有一个b()任务被加到了idle队列中,于是执行了它。
当然,如果渲染完之后发现马上又要进行下一帧渲染了,那么这个时候b()就只能继续等,一直等到浏览器有空闲时才会被执行。这个一直等有可能会导致该任务丢失,所以在react实现的时候考虑到你总不能一直不渲染某些变更,所以自己设计实现了一套任务优先级策略,随着时间的推移,越老的任务优先级越高,甚至有可能从空闲任务中拿到主线任务中被执行。
除了requestIdleCallback之外,还有一个叫requestAnimationFrame的接口,可以让一个任务放到下一帧的主线任务中去做,比如你有一个函数不需要被马上执行,但是必须在下一帧渲染前完成处理,就可以使用它。
这种利用浏览器能力的性能优化策略需要我们多学习,多了解浏览器的接口。
# 前端多线程编程
我们通常讲JS是单线程,是从JS引擎线程的角度出发去看,但自从浏览器提供了Worker标准库接口,就让我们拥有了让JS在另外一个线程运行的能力。JS引擎线程被称为主线程,其他worker线程则依赖于主线程工作,另外有一个特殊的worker是serviceworker,它具有更高的权限,即使主线程停止工作,它仍然能持续生存。
# 基于WebWorker完成大计算
你可能很难想象,前端能有什么大计算呢?我举几个例子,比如遍历一个10万+行的数据,并算出一个指标进行显示;比如对用户将要打印的pdf进行水印处理;比如对图片或视频进行转换,等等。当然,有的时候一些用于处理业务的算法也可能存在较大的计算量。我们就可以讲这些大计算迁移到webworker中。
我们需要理解,把大计算迁移到webworker,并不意味着不需要消耗资源,相反,线程间通信和延迟,浏览器对多开线程的限制等等,实际上都会降低浏览器(或者说CPU)的处理能力。最主要的原因在于,当我们把这种可能需要长时间进行计算的运算迁移出主线程之后,就可以让主线程不阻塞渲染,可以给用户一个loading效果等待计算结果,而如果放在主线程,那么这个loading都是无法被执行的。
# 基于WebAssembly处理计算
WebAssembly是前两年才开始被广泛应用于正式环境的技术,它通过把C、C++、python、rust等语言的程序编译为webassembly程序,加载到浏览器中使用,通过一些框架向JS程序暴露接口,在JS代码层面调用这些接口,就可以绕开JS引擎,使用webassembly虚拟机执行由更底层的原生语言编译的程序,从而获得更高效的性能。例如知名的视频处理软件ffmpeg、知名图像处理软件opencv,都有对应的wasm版本,通过加载这些程序,就可以在前端调用它们的接口,对视频、图片进行处理。
当然,wasm同样面临着通信上的性能瓶颈。从主线程将需要进行处理的数据传输给wasm虚拟机,处理完之后又把结果数据传回主线程,这个过程实际上效率不高,处理不好反而由于这个过程,导致性能的急剧下降。
# 基于GPU处理计算
这里我可不是在讲css的GPU加速,而是指将一些大计算交给GPU来处理,从而释放CPU的占用,CPU+GPU实现双工。知名机器学习框架tensorflow的js实现,在浏览器端就可以采用GPU模式进行运行。我们知道机器学习本质上就是通过拼命计算的苦力活,来在大量的尝试中找到最优解。除了机器学习外,区块链挖矿也可以采用GPU模式进行计算,从而释放CPU的资源占用。当然,如果你需要同时使用photoshop等大型图片处理软件或视频处理软件,那么就不能再去抠GPU的份额,因为GPU的成本是很贵的,我们普通电脑上,独立显卡往往都非常贵,想要达到和CPU的运行效率一致的GPU,那是天价才能做到。因此,实际上我们把计算交给GPU,前提是在GPU空闲的情况下才能如此去做。
未来,浏览器将开放完整、稳定的webgpu能力给到前端开发者,届时,我们就可以采用一定的策略,将一些可以从CPU中剖离开的计算放到GPU中进行,依赖一些gpu框架,我们可以用一种比较优雅的语言去进行一些图形处理的计算,gpu在图形图像处理上有明显的优势。
# 优化线程间消息传递
前文多次提到,两个线程间通信是比较慢的。那么有没有什么办法可以优化呢?实际上真没有,线程间通信慢是目前来讲无法逃避的。我的个人建议如下:
- 传递更小的数据量,把不需要的进行剔除,有些东西其实可以合并起来用一个符号来表示,没有必要非得把数据细节表现得那么丰富
- 使用序列化的字符串作为传递的消息体,两边各自进行序列化和解析,虽然序列化和解析的过程会消耗性能,但是字符串传递更快呀
当然,还有一些其他策略,例如通过切割buffer分片传递的形式等等,操作起来比较复杂,可能等到你开始去在项目中实践类似的场景时才会用到。
# V8简介与性能陷阱
作为最知名的JS引擎,V8在PC端具有绝对的统治地位。首先需要区分JS引擎和JS运行时平台的概念,JS引擎用于运行JS代码,例如V8、quickjs、Hermes、JSCore等,JS运行时平台用于提供可用于生产环境的软件基础平台,例如chrome、nodejs等等。不过随着各类场景的出现,新出现的JS引擎也附赠了一些超出ES标准之外的能力或接口,例如quickjs、Hermes都提供了比ES标准多出那么一些些的接口,用于方便开发者快速启用。不过和运行时平台相比起来,JS引擎只是一个引擎,是被平台调用的部件之一。在有了这个概念基础上,我们在下文的探讨中,就不会分不清到底是在聊V8,还是在聊Chrome。在接下来的几章,我们会去探讨运行时性能优化,但在本章,我们只会探讨JS引擎,因此,在阅读接下来的内容时,脑海中要先抛开Chrome,把眼光投到更底层的V8上。
# 关于V8
V8实现了ECMAScript和WebAssembly,可以独立运行,也可以嵌入到任何c++应用中。独立运行可能你还不了解,加入我们现在有一个v8的命令行工具,同时有一个用ES标准写的js文件,我们可以通过运行 v8 test.js 来运行这个js脚本程序。当然,由于V8只是引擎,它只能对js进行运行得到运行结果,而无法进行浏览器中的绝大部分操作(前面我们讲过浏览器渲染进行中有众多线程,类似我们常见的DOM、canvas、网络请求等等,都是JS引擎之外的由浏览器提供的能力)。
V8编译并执行JavaScript源代码,处理对象的内存分配,并负责回收不再需要的对象。在V8之前有很多其他的JS引擎,例如曾经的IE、firefox所使用的引擎,V8具有良好的性能让chrome一举击败了这些浏览器,逐渐V8和chrome具备了统治地位。它的良好性能主要体现在如下几个方面:
- 编译(JIT)而非解释执行JS,并且在编译时进行优化,从而提升运行时性能
- 一站式、分代的、精确的垃圾收集器
- 内嵌缓存
- 隐藏类
以上都是V8有别于以前传统JS引擎的地方,也是其性能胜出的关键要素,当然,每一项都具有非常深的原理,对于前端同学而言,只需要了解即可,毕竟我们都不是去做V8源码开发的。
以前我们经常挂在嘴边讲“JS是一门解释型语言”,但是V8出现之后,这个说法变得不那么正确。诚然还有很多引擎是解释执行JS的,但是对于V8而言,它采用了运行时编译生成机器语言,然而这里非常有意思的一点是,由于JS执行环境的特殊性,一般我们都是下载代码,然后马上就要执行它,所以它没有生成字节码,而是完成编译后立即运行。不过随着webassembly的发布,这个规律又被再次打破。wasm文件可以被认为就是字节码文件,且可以被V8提供的wasm虚拟机执行。当然,我们很少,或者说不可能把js编译为wasm。如果阅读过我的公众号文章《用AST实现简易的中文编程》一文,就肯定了解编译的一般原理。我们知道编译要经历tokenize->parse to AST->traverse to modify AST->generate new code这几个大的步骤,然后生成的代码就是中间代码或常被称为字节码,如果要运行,就拿着字节码到虚拟机中运行,但是V8没有这么干,它没有生成字节码,而是直接生成机器语言,拿着生成好的机器语言丢给底层的处理器进行处理。虽然它也就把编译的整个过程走一遍,但是它不会生成字节码文件,也没有虚拟机,所以这种形式被称为JIT。
独特的垃圾回收机制也是V8的拿手绝活,它通过精妙的GC(Garbage Collection 垃圾回收管理)实现,自动侦测和释放内存,而且V8采用了GC中较为激进的Generational GC模式,这种模式实现起来难度更大,但是性能上的收益也很明显。有兴趣的读者,可以专门搜讲V8 GC的文章来深入了解。
内嵌缓存则是V8的一个高招,因为我们写的大部分代码中,一个变量的类型往往是可以被推断的,一旦可以确定变量的类型,那么在某些具体操作时,我们就可以快速决策使用什么算法。比如a和b两个变量,我们执行代码 a + b 时,如果我们事先知道它们都是数值,那么就可以使用数学层面的加法,通过直接操作内存完成相加,如果我们事先知道它们都是字符串,那么久可以使用字符串的连接算法。V8做了一个取巧的设计,在编译阶段对变量类型做推断,如果变量的值在整个程序生命周期过程中都是相同类型,那么就在后续的计算中采用相同算法,这样就可以更快的执行部分代码。这使得JS作为一门动态类型语言,却可以在某些细节上拥有静态类型语言的表现。
隐藏类则是V8针对JS作为动态类型语言,“一切皆对象(Object)”的一种策略优化。从对象上读取属性、修改对象属性,都需要依赖hash算法,这是作为对象存储的数据结构所决定的。而V8做的优化,就是在一个对象的背后用一个类对它进行描述,当然,这个类对于我们写JS代码的人而言是不可见的,所以它是“隐藏类”,如果对象的描述是相同的,那么在读取其属性时,就可以直接通过该类获得信息,而无需对对象进行遍历。要知道,在JS里面,几乎所有的东西都是对象,比如函数、字符串、数字,有了隐藏类,在其属性读取时就多了一层性能上的提升。
当然,这些知识远不止这么简单,我在这里的描述是按自己的理解来表达的,方便读者有个初步的映像。如果存在出入,欢迎指出。
# V8性能陷阱
虽然通过上文,你会觉得V8非常牛X,但是我不得不提醒你,凡事都有两面性。我们写代码过程中如果做了某些特别的操作,那么不仅不被优化,甚至有可能会由于V8的这些机制,反而降低其性能,所以实际上V8也保留了解释运行的能力,在一些特例下面,解释运行比JIT更快。以下是我总结的一些性能陷阱,你应该尽可能的避免:
- 使用eval来运行代码。注意,这种代码不会被优化,而且还不够安全。
- 使用debugger来调试代码。注意,含有debugger的函数整个函数都不会被优化。
- 使用with语法的语句。注意,with语法整个语句块都不会被优化,大部分微前端框架都是用with将整个子应用代码进行包裹,所以存在性能坑,需要我们自己注意。
- 使用__proto__作为对象属性。注意,生命对象字面量或class时,含有__proto__属性的,整个对象都无法被优化。通过Object.setPrototype重置原型链的对象也不会被优化。
- 在代码运行过程中,赋值为初始类型之外的其他值。注意,变量被赋值为非初始类型值,优化将被取消。解决办法是,当需要切换类型赋值时,使用一个新变量代替。多用const。
- 在函数中使用arguments。注意,函数体内使用arguments读取参数的函数整个函数都不会被优化。使用...args代替(当然,使用babel又回去了)。
- for...in,整个函数不会被优化
当然,还有一些针对V8策略的优化建议,比如使用尾递归啦,上面提到的变量赋值换一个新变量啦等等,这些都是针对V8的建议,其实不算是任何条件下都应该考虑的,因为我们在手机端开发的时候,手机应用往往内置了一个其他JS引擎,这个时候,你的这些针对性优化就会失效,所以,关于此类针对性建议,了解一二即可。不够并不是说上面的这些陷阱可以随便用,这些陷阱可以说在哪个JS引擎中,都同样有借鉴意义。
# 深入理解JS堆栈与作用域
如果我们仅仅满足于表面的性能优化工作,那么前面的知识已经足够你在工作中应对很多问题,然而到了具体的一些有难度的代码层面的性能问题,则难以解决。想要能够让我们写出高性能的代码,或者说合理的代码架构来提升性能,就需要我们深入理解JS的运行机制,而想要掌握JS运行机制,就需要更深入的理解JS堆栈和作用域这两块知识,虽然这两块知识不是性能问题知识本身,但却是性能优化的底层依据。
# 深入理解JS堆栈
JS虽然是一门高级语言,开发者不需要像C语言对内存进行控制,但是在写JS代码时,脑海中仍然应该有一张变量内存空间的图,以避免过多内存消耗,甚至出现内存溢出等情况。
虽然我们很少在编程中提到JS的内存空间,但是它真实存在,必要的时候,你必须理解它才能解决工作中遇到的问题。JS中,内存空间分为“堆内存”(heep)和“栈内存”(stack)。其中“栈”直接存值,因此读取更快,而“堆”是将值存在一块更大的无序内存上,以键值对的形式存储,再以“指针”(或叫“引用”)的方式把该值所代表的堆内存空间交给其他变量的,所以用“堆”存储的变量在读取时,实际上先拿到“指针”,从内存空间中去找出该指针所引用的那一段堆内存空间,再将该内存空间中的值读取出来。而由于这种键值对的形式,只传递“指针”,因此,当我们对存储在堆内存中的一个值进行修改时,常常只是把一个变量的引用指向另外一个值,也就是把这个变量从一个“指针”替换为另外一个“指针”,而对象所在的内存空间并没有发生变化,这就导致我们在修改对象的属性值时,该对象并没有发生任何的变化,只是属性(作为堆内存变量)从引用一个值变成引用另外一个值。在JS语言中,绝大部分的存储都是堆存储,因此我们讲“JS中一切都是对象”,同时我们也讲“JS中大多是引用型变量”。
这样用文字表达你可能会很懵圈,接下来,我们用图文举例来详细阐述这一知识。
var a1 = 0; // 栈
var a2 = 'this is string'; // 栈
var a3 = null; // 栈
var b = { m: 20 }; // 变量b存在于栈中,{m: 20} 作为对象存在于堆内存中
var c = [1, 2, 3]; // 变量c存在于栈中,[1, 2, 3] 作为对象存在于堆内存中
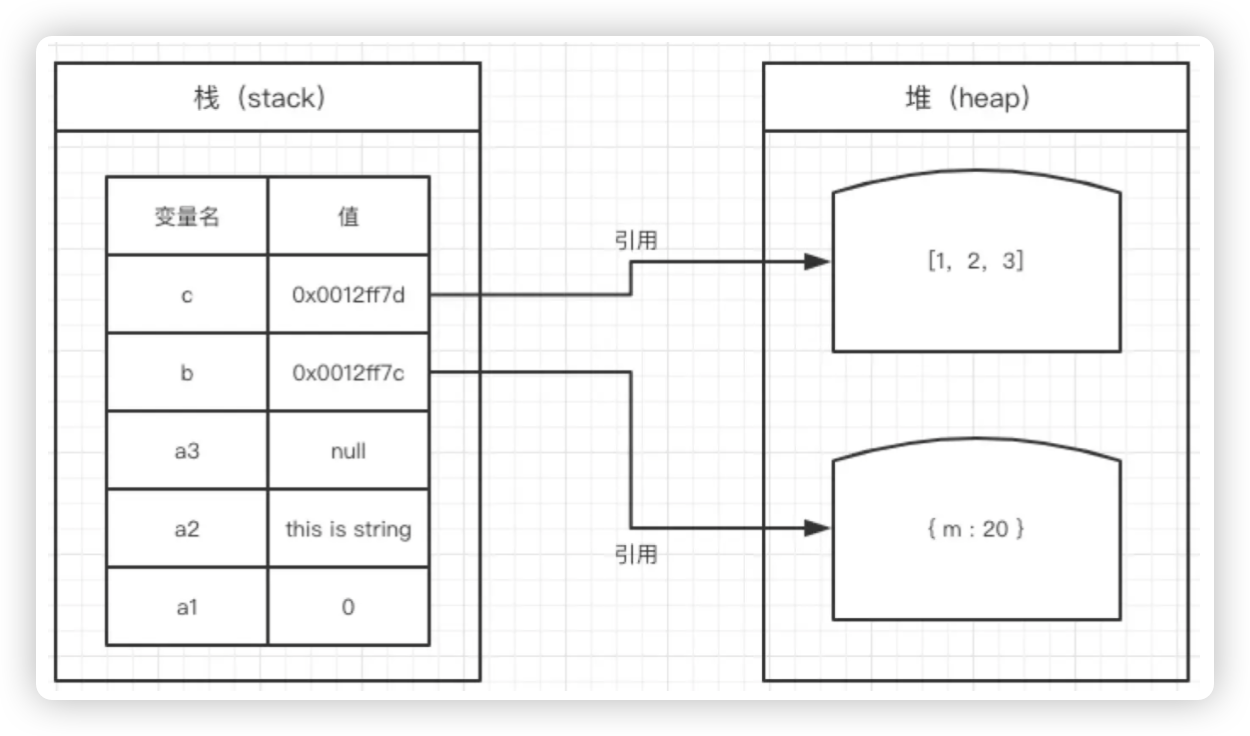
上图可以看到,b和c的值实际上是两个指针,它们分别指向堆内存中的两块空间。我们知道,JS中目前有7种基本数据类型,除了这些基本数据类型外,其他所有值都是对象,如果变量的值为基本数据类型,就可以直接存在栈上。栈的速度比堆快,但为什么快这一点大部分教材都不会讲。我们都知道栈是后进先出的特性,但是这个特性在读写内存时根本帮不上忙。但在理解堆为什么慢之后,或许栈的优势才能体现出来。当我们读取对象的属性值时,首先通过对象变量读取它所引用的堆内存地址(开头地址),然后获得该属性名的hash(hash算法又用到一定的性能),遍历该块空间,找到该hash所对应的值,返回该值。如果该值是另外一个对象,那么上面这套过程还要再走一遍。所以在堆内存中找到一个值,要比直接在栈中找到一个值,可能花掉的步数会多很多。
但是,在JS中使用对象又有一些特别的性质。让我们看一道面试题:
var a = { n: 1 }
var b = a
a.x = a = { n: 2 }
console.log(a.x);
console.log(b.x);
请问此时a.x和b.x的值各是多少?
这道面试题在大部分刚入行的小伙伴脑海中完全没有概念,他们会想“你想表达什么?”但是,如果我们积累了JS堆栈相关的知识,就可以很容易答出。b = a这一句看上去是赋值,但实际上a变量在内存中仅仅是引用了一个“指针”,b变量仅仅是获得了a变量所引用的这个“指针”,因此,我们可以发现a和b是的值是完全相同的,这和 x = y = 1 还不一样,x 和 y 的值都是1,但它们被存在栈内存中,所以实际上它们消耗了两块内存空间,但是 a 和 b 只消耗了一块内存空间,这块内存空间的“指针”被 a 和 b 同时引用,所以我们可以说 a 和 b 的相等比 x 和 y 的相等更相等。
当我们使 b = a 之后b就引用了和a相同的堆内存空间,所以,当修改a的x属性时,对于b来说x属性值也随之变化。这种引用特性在很多场合非常有用,它甚至可以节省内存占用空间。这听上去非常简单,而且我们在JS中司空见惯,但是实际上在其他语言中就不一定是这种设定,比如在php中 b = a 代表着会把a的内存整个复制一份后再给b,这意味着修改a跟b没有任何关系。
执行 a.x = a = { n: 2 }:
由于赋值操作是从右向左执行,所以 a = { n: 2 } 首先执行,此时 a 被更新为指向新对象 { n: 2 }。
然后执行 a.x = a,由于这一步是在赋值之后进行的,这时 a 已经是指向 { n: 2 } 的,但实际上,这个步骤是尝试在原始 a 所指向的对象上设置 x 属性(即 { n: 1 } 对象)。
这一步的执行是基于 a.x 的解析时刻在赋值 a = { n: 2 } 之前,所以它实际上修改的是原始对象。然而,由于我们后续访问的是新 a 对象的 x 属性,而新对象并没有 x 属性,所以 a.x 返回 undefined。但是由于修改的是原始对象,b指向了a的原始对象,因此最后b对象是有x的值的,b.x = {n:2}
# 执行上下文
“上下文”对应的英文context实际上比较难翻译,这使得我们对“上下文”的理解比较模糊。实际上,我们可以用“环境”来替代“上下文”的概念,这里的环境,即用于为执行程序提供所需要的资源的环境,环境资源包含内存、CPU、网络等,在这些资源基础上,环境基于引擎机制去调动、读取、写入、管理计算资源,从而让程序跑起来。
执行上下文主要有三种:全局执行上下文、函数执行上下文、eval执行上下文。实际上全局执行上下文也可以被认为是一种特殊的函数执行上下文,可以认为是java里面的main函数,即入口函数。在这三种上下文中,都包含如下三个重要内容:
- 变量对象
- 作用域链
- this
你可以把它们也认作是资源,但是这些资源是临时创建的,是软件性质的,等程序执行完就会销毁的。
一个执行上下文的生命周期包括:
- 创建:变量声明、函数声明、初始化函数参数arguments;创建作用域链;确定this指向
- 执行
- 回收
一个执行上下文总是为一个函数(我们把全局global当作main函数)服务的(在函数执行之前被创建),所以当需要执行一个新函数(或子函数)时,就会创建一个新的执行上下文。这些执行上下文以栈的形式被管理起来,被称为“执行上下文栈”,或更常听到的“调用栈”。全局global总是在栈底,当有新的函数需要被执行时,为该函数服务的执行上下文被压入栈顶,在这个执行上下文中有各种变量或函数参数,它们被分配了内存。当函数执行完毕,这个执行上下文就会被从栈顶弹出,弹出之后其内部的变量就会被放入垃圾回收任务中,等待被回收(当然,还有特例,下文讲)。
调用栈还涉及事件循环、宏任务、微任务、异步等知识,这些知识串联在一起,组成了我们对“JS代码所代表的程序是如何被执行的”的完整知识体系。
# 深入理解作用域
作用域是JS里面非常难理解的部分,我试图说的简单些,不想教条的重复某些难以理解的话术。简单讲,作用域是指“当前程序的可访问变量的集合”,它包含三层意思:
- 当前程序:全局、函数、块级代码
- 变量集合:变量名(标识符)有哪些?
- 可访问:并不是所有变量在当前程序都是可以访问的,当前作用域只提供当前程序可访问的变量集合
和执行上下文不同,作用域是在函数定义时就已经确定了的,而不是等到函数执行时才确定。你可能会问,那么为什么我调用函数的时候,读取变量的值不一样呢?因为变量的值不属于作用域管理的范畴,作用域只管理变量(标识符)的可访问性,而不管这个变量具体被赋予什么值。比如下面这段代码:
let a = 1
function add() {
let b = 2
a += b
}
function minus() {
let c = 3
a -= c
}
add()
这段代码里面,函数add在定义时就确定了其作用域,该作用域包含了两个可访问变量a,b,但在执行add函数之前,它并不关心a,b到底是什么值,它只关心“在add函数执行时,其内部只能访问a,b两个变量,无法访问c变量”。这里的访问包含多层意思,即读取、写入等操作。
一个函数的作用域可以被多个执行上下文使用,作用域类似一个地图,让执行上下文从中正确读取变量。
前文我们讲到JS实际上现在也是一个半编译的语言,一段JS程序要经历“编译->执行”两个阶段,而作用域的确定就是在编译阶段,JS引擎通过解析JS脚本,便能梳理出一段程序的作用域,不需要等到执行该段程序时才能确定作用域。从这里我们可以发现,JS引擎必须把所遇到的全部变量(标识符)记录下来,才能准确创建作用域,由此可见,JS这门语言在这个点上是比较消耗资源的,这都是由该死的全局作用域的设计导致的,在很多其他语言中,函数内是无法读到函数外定义的变量的,没有全局和局部变量之分,作用域仅限于函数内部,但是在JS中,从最顶层的全局到最底层的函数,中间即便是有无数层,引擎都需要在作用域中把这些变量收集起来,提供给当前程序使用,为了节省,它又搞出了一个“作用域链”的概念,当前作用域处于一个作用域链中,访问一个变量时,会从当前作用域不断往链的上游查询,直至查完顶层的全局作用域还没有找到该变量(标识符),才会报错说变量未定义,抛出一个ReferenceError: ${var} is not defined错误,可见这种设计效率非常慢。可是很无奈,这一糟糕的设计已经成为JS语言最基础的特性,不可能再被修正,我们只能接受它。
关于作用域,我们还需要了解:
- 全局作用域
- 函数作用域
- 块级作用域
- 变量提升
- 作用域链
这些知识构成了我们对作用域的全部理解。需要注意的是,前面我们讲作用域是在函数定义时就已经确定好的,但是作用域链不,它是在执行上下文被创建时创建的,并被挂在一个特殊的属性[[Scope]]上面。
# 垃圾回收
“垃圾回收”英文是 Garbage Collection,即我们常说的GC,中文翻译我认为非常精确且巧妙。GC不是JS独有的特性,很多现代编程语言都有GC,比如rust,而且不同编程语言的GC机制不一样,不过在我看来,JS的垃圾回收做的非常优秀,虽然有的时候也会遇到内存被拉满,但是对于编程而言,我们可以做到写代码随心所欲不逾矩。
前文提到,JS引擎在执行程序时,经历了执行上下文的“创建->执行->回收”三个阶段,当程序执行完毕,JS引擎就会开始对已经使用过的执行上下文进行回收。这里要回收的“垃圾”只要是指“不需要再被使用的变量或函数”。那么引擎怎么知道变量或函数不再被需要了呢?它需要通过一些策略来做到。这些策略包括:
- 标记清理:分代收集、增量收集、闲时收集
- 引用计数
垃圾回收是引擎自己在后台执行的,不需要我们在代码层面手动调用。但并不意味着我们不需要在代码层面为垃圾回收做准备,我总结了一条铁律:
- 当使用完非自己所在作用域的任何变量时,都要将它交还
这条铁律的意思是,在你的函数中使用了一个外部变量时,无论什么情况下,你都要考虑在函数结束时,对这个外部变量进行处理,如果这个外部变量引用了一个对象,此时,你需要考虑是不是要把它置为null。当然,并不是说每一次都要置为null,而是你需要考虑这件事。无论是标记清理,还是引用计数,垃圾回收都需要去确认我的所有变量中,哪些是不在需要被使用的。这里不再需要被使用,并不意味着变量绝对不能被其他变量引用,例如下图中右侧的三个对象相互引用了,但是通过标记,引擎发现它们不会被当前程序再次使用,所以就认为它们需要被回收。
用同样的定律,我们可以解决引用计数中循环引用的问题,假如a.b = b同时b.a = a,那么,我们在程序结束时,要同时对a和b进行操作,a.b = null; b.a = null 而不能只操作其中一个。这些原则性的编程习惯需要我们在长期实践中养成。
# 闭包
闭包(closure)其实并没有一个很严格的官方定义
如果粗犷一点回答:“其实任何函数都可以是闭包”
当然,如果这是一个面试,我觉得应该回答到让面试官理解,能听懂,并且很舒服的回答
“闭包是指有权访问另外一个函数作用域中的变量的且交由其他执行上下文执行的函数。”首先,闭包是一个函数,其次它有两个要点:
- 有权访问其他函数作用域中的变量(其实大部分情况是作用域链上游的变量)
- 交由其他执行上下文执行(不交给其他执行上下文的无所谓闭包)
我们来举个常见的例子:
function plus() {
let a = 0
function add() {
a ++
return a
}
return add()
}
plus() // 1
上面这个例子中,add函数引用了plus函数中的a变量(有权访问),但在调用plus()时,add函数被plus执行上下文执行了,虽然我们说它引用了其他函数作用域中的变量,但是它没有产生实际的效用,因为它没有交给其他执行上下文执行,而是在当前执行上下文中被执行了,所以,我们可以称它为闭包,但是没有实际意义。
function increase(a) {
a.count ++
}
function plus() {
let a = { count: 0 }
function add() {
increase(a)
return a.count
}
return add()
}
你看,这个例子里面,我们在add函数中引用了来自其他函数plus所在作用域的变量a,甚至还交给了另外一个函数increase去修改,但是在整个执行过程中,它仍然没有产生实际的效用,我们可以把increase函数称为副作用函数,也可以把add函数称为闭包,但是没有实际意义。
function plus() {
let base = 0
function add(x) {
return x + base
}
return add
}
const add = plus()
add(3) // 3
add(4) // 7
上面这个add函数引用了来自plus函数作用域的a变量,同时交给plus函数作用域的上一级执行上下文去执行,所以这是一个正宗的有实际意义的闭包。
闭包有很多应用场景。我们前文讲,函数执行完进入回收阶段,执行上下文被销毁,其内变量被回收,但对于闭包所引用的其他函数作用域内的变量,由于垃圾回收机制取决于该变量是否还需要被使用到,很明显,这些变量还会被使用到,因此无法被垃圾回收。如果闭包被交给全局,那么闭包所引用的变量就永远无法被回收了,就会导致严重的内存泄露。如果在我们的程序中,存在巨大的内存泄露,就会严重影响性能。
# 算法
算法有两种,一种是为了实现之前无法实现的算法,一种是为了优化之前不够好的算法。
# 优化循环迭代
日常开发中,我们100%会用到循环迭代。但凡用到,我们就会不经意的问自己,它会被运行多少次,会不会因为反复运行而造成性能问题。造成循环迭代性能问题的决定因素有两个:迭代次数,单次迭代的复杂度。我们可以用公式“循环迭代性能=单次迭代复杂度x迭代次数”来表达它们之间的关系。其实这非常容易理解,迭代的次数越多,性能越差,单次迭代运行消耗性能越多,总体消耗性能越多。因此,我们的优化方案就围绕这两个因素展开。
首先,降低单词迭代的复杂度。
我们可以用到两个技巧:事务提升;倒序迭代。
事务提升是指把一些事情提升到循环体之外进行,而不要在循环体内去做这些吃力不讨好的事情。比如我们常见的写法:
for (let i = 0, len = items.length; i < len; i ++)
其中我们把获得items长度的动作前置到循环开始,而非每次判断循环是否需要结束时再去读取长度。当然,对于现代浏览器而言,此处的优化所带来的性能提升微乎其微,但是思路上就是希望你能过把一些固定的事务,从循环体中脱离出来,有的可以提升到前面,有的可以在循环体中只拿到一些信息,等循环结束之后再利用这些信息进行计算,而不是在循环体内实时进行计算。
倒序迭代是指从后往前迭代,在一些特定的查找场景下非常有用且高效。它的大致写法如下:
for (let i = items.length; i --;) {
const item = items[i]
...
}
这里使用了非常有意思的技巧,我们没有给for第3段,而是在第2段中使用了后置自减操作,前置自减和后置自减的区别在于,前置是返回运算后的值,后置是返回运算前的值,所以我们这里用返回运算前的值作为判断循环是否要继续的依据,当i为0时会自动跳出循环,而在循环体内的i则是已经完成自减运算的值,所以items[i]中的i值其实比i--的值小1.
倒序迭代在进行某些查找时,可以从末尾进行查找,在找到之后可以尽快break,从而避免遍历整个列表。
其次,减少迭代的次数。
我们可以用到三个技巧:增加步幅以减少迭代次数;循环体展开技术;提前结束遍历。
增加步幅比较好理解,我们来看一个优化的例子。
for (let i = 0, len = items.length; i < len; i ++) {
if (i % 2 === 1) {
...
}
}
这段代码中,我们通过一个 i % 2 来处理一些内容。但是对于for而言,它会迭代items的长度。我们如下优化:
for (let i = 0, len = items.length; i < len; i += 2) {
...
}
现在,我们不需要通过 i % 2 来进行判断,因为我们每次迭代结束的时候,i自增了2.所以,这个优化不仅减少了迭代的次数,还降低了单次迭代内的复杂度。
循环体展开技术是一种分批执行的技术,当我们要需要对很多元素进行遍历的时候,可以把一个复杂的循环体,拆分为多个简单的循环体,从而让单个循环体的复杂度降低进而降低整个循环的消耗。实际上,它一方面通过分批次的方式减少迭代次数,另一方面也是降低了单次迭代的复杂度。
提前结束遍历主要是利用一些迭代方式,提前结束。一种是在for/while中使用return,另一种是使用find/some等数组方法。例如下面这段代码:
items.some((item) => {
if (item.price < 13) {
process(item)
return true
}
})
上面这段代码并没有将items.some()作为if的条件进行判断,而是利用它可以通过return true来提前结束遍历的特性,只在第一次找到某个元素时执行process函数。
# 条件语句优化
if...else在我们日常开发中用的极多,可以说是我们最常用的语句。它的问题在于,如果我们没有一定的策略,会导致全部的条件都去判断一遍,如果每次判断的逻辑比较复杂,就会消耗掉比较多的性能。我们有一些策略对条件语句进行优化,主要有:优先判断高频条件;二分法思想;用策略模式干掉判断。
在一些条件需要进行计算的情况下,如果有多组条件都需要执行,就会消耗比较多性能,这种情况下,我们应该尽可能避免执行过多的条件判断。我们需要根据实际情况,将可能性更大的条件放在前面,这样,在大部分情况下,只需要执行前面几条判断就可以退出这一组条件语句,从而减少被执行的条件条数,减少性能消耗。例如:
if (condi(1)) {}
else if (condi(2)) {}
else if (condi(3)) {}
else if (condi(4)) {}
else {}
假如上面的代码中,condi(1)发生的概率并不大,那么上面的代码每次在被执行时,都会走到这一条判断,而大部分情况下都做了无用功。因此,我们可以把最常用的condi(4)调整到前面:
if (condi(4)) {}
else if (condi(3)) {}
else if (condi(2)) {}
else if (condi(1)) {}
else {}
在条件具有连续性,且条目很多的时候,它的复杂度是O(n),通过二分法的思维可以将复杂度降低到O(logn)。在大部分情况下,条件判断都是非此即彼的,因此二分法在这种场景下可以起作用。如:
if (x > 10) {
if (x > 15) {
if (x > 18) {}
else {}
}
else {
if (x > 13) {}
else {}
}
}
else {
if (x > 5) {
if (x > 8) {}
else {}
}
else {
if (x > 3) {}
else {}
}
}
通过这种二分法思维,在一些情况下可以使得判断次数减少。但是也要注意,这也意味着它的判断数量是一定的,也就是说用正常的条件判断可能只需要判断2条,而这种判断方法不得不判断5条后才得出结论。
另外一种技巧是采用mapping来避免条件判断,这种方案在某些场景下也符合策略模式的。具体操作如下:
switch (a) {
case 1: do1(); break;
case 2: do2(); break;
case 3: do3(); break;
case 4: do4(); break;
}
上面这种条件判断来执行对应函数的方式并没有什么不好,但是每个case都会跑一遍判断过程。如果我们把它优化为如下:
const dos = {
1: do1,
2: do2,
3: do3,
4: do4,
}
const dofn = dos[a]
dofn?.()
则不需要任何条件判断,而是通过读取mapping上的函数来执行。这种技巧适合a的取值是固定的,其形成的条件是离散的。这种方案直接干掉了条件判断,这样就可以大大提升程序的执行效率。
# 使用递归
简单讲,递归就是在函数内部调用函数自身的行为。前面我们讲过,执行上下文是在函数开始执行前创建的,我们通常会在递归中通过判断条件跳出递归,但是由于递归函数的执行意味着执行上下文的复制,在执行栈中不断入栈新内容,从而占用大量资源。它对内存的开销与递归函数的执行次数成正比。而如果处理不当,没有跳出递归,就会导致“死循环”。现代浏览器对“尾递归”进行了优化,所谓尾递归就是在函数的末尾把递归进行返回,例如下面这段代码:
function a() {
if (!x) {
return
}
return a()
}
我们前面讲到作用域和执行上下文的关系,浏览器正确识别这是尾递归后,可以不需要反复的去确认其执行上下文。
# 优化字符串处理
字符串处理主要包括合并、搜索、剪切、重排、遍历等。要提高字符串处理的能力,我们需要掌握一些技巧。常用技巧有:
- 使用索引
- 将字符串转化为数组,再用数组的方法进行操作,最后再join('')连接回字符串
- 搜索时从字符串中间开始,采用二分法
# 优化正则表达式
正则表达式是非常复杂的一套知识体系,要掌握它的细枝末节,我们可能需要读一本书。坏的正则表达式,在运行时很消耗性能,当然,为什么消耗性能,需要我们去理解正则表达式的查找实现的算法,本册无法提供完整的解释,因此,这部分内容需要你作为课外知识去补充。我们提供一些优化正则表达式的建议:
- 不要写过长的复杂的正则表达式,不要以为用一个正则表达式能做到的就一定要用一个正则,有可能你把这个匹配拆分为多个步骤,效率可以翻几十倍
- 相同的正则表达式赋值给一个变量重复使用,否则在遇到正则表达式时其引擎需要重新编译,浪费资源
- 更快结束匹配,就和前文优化if...else一样,如果你可以让正则表达更清楚,让它在匹配时尽快发现无法匹配,以结束匹配的话,就一定要这样去做
- 减少分支数量
- 尽量具体
正则表达式和自己写代码实现,有的时候要看具体情况,说不定虽然自己写了看上去比较丑的代码,但是相对于正则而言,效率更高。
# 缓存
和网络缓存不同,我们在客户端甚至代码层面会用到一些缓存技术,这些缓存技术让我们可以更高效的去执行某些动作,从而让使用我们应用的用户感受不到该技术的存在,但却认为应用变快了。当然,缓存也存在一些缺点,因此,我们在实施缓存技术时,要有选择的优化缓存策略。
# 运行时缓存技术
在代码中,我们会反复的执行某些技术,但如果基于相同的技术,且内容相同的话,就会导致重复计算,这些计算其实是没有必要的,因此我们可以把它们缓存起来,在第二次计算时直接使用缓存。例如:
const items = [1, 2, 2, 5, 3, 2, 4, 1]
const results = items.map(processor)
在上面的代码中,items中有重复的2和1,假如processor是一个计算量庞大的计算过程,那么,这些重复的计算,就可以使用缓存。我们可以采用一种基于参数的缓存方案:
let cache = {}
function processor(num) {
if (Object.prototype.hasOwnProperty.call(cache, `${num}`)) {
return cache[num]
}
const result = ...
cache[num] = result
return result
}
processor.clear = () => cache = {}
const items = [1, 2, 2, 5, 3, 2, 4, 1]
const results = items.map(processor)
processor.clear()
我们使用了一个cache来保存每一个参数对应的计算结果。但是需要注意,我们应该提供一个clear方法,因为如果我们长期不清理cache,就会导致内存溢出。通过这样的改造,就可以让我们的程序避免重复的计算。
运行时缓存策略非常多,且很难一一举例,我们应该在开发中不断去尝试和优化,而不是限于上面这一种场景。例如react提供的useMemo,就是一种非常有意思的缓存方案,在react退出hooks之前,社区提供了一种叫reselector的方案,它的效果和useMemo或者memo很像,但是用法上却没有useMemo那么简洁。这说明在我们的开发中,我们可以去优化缓存方案,使它既能提供高效的运行性能,又有更好的开发体验。
# 前端持久化存储
所谓持久化,就是当应用被卸载时,其存储仍然还存储。这里的卸载包括刷新页面、关闭tab、关闭浏览器等操作。我们常见的持久化存储有cookie、sessionStorage/localStorage等,另外还有indexedDB
你应该如何选择使用哪一种作为持久化缓存呢?
- cookie: 尽量不用,除非在涉及前后端交互时不得不用的情况下
- sessionStorage: 当你希望用户刷新页面保持存储,但关闭页面后清空存储时使用
- localStorage: 当你希望用户关闭后保持存储,再次打开时还存在的情况时使用
- indexedDB: 当你希望存储比较多的数据,有条理的管理它们时,使用indexedDB,它像一个真正的前端数据库一样,具有记录的性质,可以创建便捷的条件查询
# 高性能架构
当我们使用某些细节的技术仍然无法解决卡顿、慢等问题时,我们就应该考虑,是否是因为我们所设计的整套技术实现本身就存在问题,或者说我们的架构不够高性能。在react推出16版本之前,它使用了经典的virtual dom架构,通过diff和patch两套动作实现DOM的更新,然而随着react应用暴露出越来越多的性能问题后,核心团队成员发现diff和patch占用了长时间的计算,导致diff和patch这两个过程,浏览器都处于等待状态,也就是卡顿。为了解决这一问题,react推出了新的fiber架构,对diff进行大刀阔斧的重构,实现了时间分片等特性,让diff和patch两个阶段分开调度,从而释放了长任务,除了操作DOM本身可能带来的卡顿,基本上就不存在长任务,因此,拥有更高的性能。我认为,从应用整体层面去规划,实施高性能架构,是让应用拥有性能底线的基础,如果应用架构本身就是低性能的,那么再怎么优化,都无法突破架构性能的下线,架构本身就已经让性能的瓶颈卡在那里了,你无法获得更高的性能。因此,在应用架构设计阶段,有判别高性能架构的思维,是非常重要的,因为架构一旦确定,就会永远影响应用的性能。
我们无法断定哪一种架构性能更好,同时,不同的场景下设计不同的架构来实现我们的目标,所带来的副作用也各不相同。例如同样是面对整个应用代码结构庞大复杂的问题,我们可以采用分层架构,也可以采用微前端架构,或者组件-应用架构,即使都采用微前端架构,我们所选型的微前端框架也会影响我们的代码结构,最终所表现出来就是性能不同。一般而言,越接近原生,性能越好,但是编写过程越头疼,而抽象度越高,往往性能劣势更明显,此时,常常需要做一些巧妙的设计,来让开发者可以自己实现性能的提升,例如从框架内部提供一些方法,开发者一旦使用这些方法,就会让框架运行时采用缓存策略,从而加速性能。
接下来,我将简单介绍几种架构设计的思路,这些思路都是从性能角度出发提供建议。
# 无状态化架构
前端也开始流行函数式编程,其中的重要思想之一就是无状态化。这里的无状态化并非指整个应用中不存在状态,而是将状态统一交给一个状态管理器去管理,而此外的其他部分全部按照函数式的思维,驱动整个应用的不断流转。
无状态化架构之所以有较高的性能,原因在于编写程序时,我们会刻意的控制内存占用,由于状态交给统一的状态管理器管理,也就意味着当前程序本身在运行过程中,并不积累内存,运行完之后,内存就会被释放掉,所以总体而言,就不会出现内存溢出等情况。
当然,无状态化也有一些缺点可能会影响性能。例如我们往往追求函数的纯净性,而这种纯函数的思想,就会导致相同的逻辑,分散到不同函数中,就不得不执行两次。
# 异步化架构
前端开发是接触异步最多的开发领域,因为我们通常需要使用ajax或其他形式从服务端加载资源,而所有的这些逻辑,往往都会放在异步任务中运行。
异步化架构之所以有较高的性能,原因在于它对任务进行拆分,从而避免在同一帧执行过长的任务,进而避免的卡顿现象。
但是,异步化也会让我们的代码难以理解,因为同一任务的代码往往会被分为好几段,甚至散落在不同地方,这就会导致我们在阅读某一逻辑时,无法有一个完整的思路。
# 队列
前端很少讲队列,但是我认为队列是解决异步化架构问题的重要手段。简单讲,我们会在前端应用中构建一套队列服务,当我们需要按照队列的形式执行任务时,就将任务丢给队列服务,当任务执行完时,又会回到原始的位置继续执行。队列具有先进先出的特点,因此,在一些需要按照顺序进行执行的场景非常有用。同时,我们还可以基于参数对任务进行分类,假如同一任务被再次push进队列时,我们可以采用提升上一个任务的优先级的策略,让上一个未完成的任务马上执行,然后再把当前这个任务push进队列;当然,我们也可以把上一个任务直接丢弃,使用新任务的结果。
队列之所以具有较高的性能,和异步化架构是一致的,都可以起到通过时间分片的方式,拆分大任务,让一个可能占用长时间的任务,分为几段来执行。
# 协程
协程在前端场景下是指在多个任务之间调度,以实现类似并发的效果。我们知道js执行是单线程的,这也就意味着如果不加处理,一个任务就必须从头到尾执行,导致其他任务排队等待,出现页面卡顿。而通过协程的架构,我们就可以设计出基于时间分片的多任务切换,达到类似并发的效果。这也就是react fiber的设计思路,以及新版本react中suspense的由来。
虽然ES本身有yield来实现这种简单的协程,随后又发布了await,但是从上文我们可以看到,协程架构的核心不是在实现任务的中断与上下文的保留,而在于调度。我们做架构设计的目标,不是让开发者去刻意使用协程,而是在框架内自动集成调度,让开发者感受不到协程的存在。
协程架构之所以具有较好的性能,和上面的异步化架构、队列其实大同小异,不同的地方在于,协程架构把这种任务拆分进行了重组,让开发者感受不到其拆分的过程,同时又有并发的感受。
# React性能优化
作为当下最流行的前端视图层驱动框架,react提供了一套把UI视图抽象化的解决方案。由于其高度的抽象性,导致开发者在使用过程中,常常触发一些意料之外的逻辑,从而带来不必要的性能问题。
# React渲染机制
在开始之前,我们必须了解react的渲染机制,否则我们无法正确思考和处理工作中遇到的性能问题。React的渲染,包含如下知识:
- createElement->Virtual DOM
- react生命周期
- 从Virtual DOM到真实DOM
- fiber,reconciler,scheduler
作为一个视图层驱动框架,react本身的架构可以分为3层:Virtual DOM层;Reconciler层;Renderer层。其中,Virtual DOM是react最原始最核心的概念,它用于描述一套跨平台的UI结构,注意,这里的结构包含其逻辑和事件。Reconciler层是react中最重要的,区别于其他任何基于Virtual DOM的框架(例如vue、avalon、preact等)的关键,该层用于对Virtual DOM进行处理、对比、计算,对用户事件进行调度,推动组件生命周期等等工作。Renderer层用于把Virtual DOM映射到具体的某个平台上,表现出具体的UI和人机交互逻辑,比较常见的有ReactDOM和ReactNative。
React现在的版本基于fiber架构完成reconciler层所有工作。Reconciler的主要工作是调用组件生命周期,这里可不指组件生命周期函数,react官方开源了react-reconciler (opens new window)这个库,你可以基于它了解react组件真正的生命周期。在生命周期的基础上,fiber构建了一套非常巧妙的时间切片算法,让reconciler处于一种更加灵活且掌控性更强的调度中,整个调度交由scheduler (opens new window)来进行任务分配,实现了任务的优先级,这些优先级可划分为:
- synchronous,与之前的Stack Reconciler操作一样,同步执行
- task,在next tick之前执行
- animation,下一帧之前执行
- high,在不久的将来立即执行
- low,稍微延迟执行也没关系
- offscreen,下一次render时或scroll时才执行
基于fiber的reconciler分为两个阶段:reconciliation阶段和commit阶段。其中commit阶段的主要工作是把计算后的变更实施到真实的DOM或native环境中,影响UI界面的变化,因此,这个阶段是不可以中断的。而reconciliation阶段主要工作是计算、diff、找出变更(副作用),这些计算大体上还是基于virtual DOM的,由于它属于计算层面,所以是可以中断的,react实现了巧妙的时间切片算法,可以在计算时根据任务的优先级来中断当前的计算,等到有空闲时间时再重新开启之前的计算。基于该时间切片算法,计算被合理的划分到不同时间切片,从而大幅避免了长任务所带来的卡顿现象(当然,有的情况下还是不可避免,但总体而言比较少)。
在reconciliation阶段进行计算时,react也巧妙的采用了双缓冲池算法,简单讲就是通过快照来减少内存占用。在fiber架构下,react会在第一次渲染完成时,建立一棵fiber树,reconciliation阶段会基于该fiber tree建立一个workInProgress tree(实际上就是fiber tree的快照),然后在workInProgress tree上做修改,而这个修改不会影响原来的fiber tree,当任务暂停后继续时,workInProgress tree保存了计算信息,所以,react知道应该从哪里继续计算;当被更高优先级的任务打断时,该workInProgress tree被直接丢掉,fiber tree不会发生任何变化;而如果计算顺利完成,workInProgress tree会直接替换fiber tree,从而让整个界面有新的描述,让下一次reconcile计算有快照可依。commit阶段就会基于找到的更新,对UI进行变更。
以上就是react渲染的大致情况,你会发现,在这个过程中,每一个细节,都有可能给我们埋坑,因为它涉及很多设计上的实现,它在代码上的实现是没有标准的,不同版本的react想怎么去处理就怎么去处理,因此,我们编写react组件,只能尽可能的避免直接依赖底层的算法,而应该通过react暴露出来的api来进行控制,否则一但版本升级,我们以前做的很多建设都将付之一炬。
# 常见的React性能问题与优化对策
1. 接收相同的props,却还是被重新渲染
注意,这里的重新渲染仅仅是render生命周期重新被调用,并非只真实UI被重新渲染。由于组件render时可能存在大量计算,所以一旦被反复调用,就可能引起性能问题。我们时常疑惑,为什么接收了相同的props,还是会重新渲染。注意,这里的相同props,不包含传入了看上去一样但实际上是两个独立的对象或函数的情况。例如:
<Some name="toniy" />
为什么Some组件的render会被反复执行呢?明明name是个字符串,不会变化。这是因为react在实现代码层面,仅对前后两次props进行了全等对比,即===,而组件每次执行到该生命周期时,props明显都是新创建的,虽然看上去是一样,但实际上是两个对象。如果react内部实现时,采用了shallowEqual,那就不存在这个问题了。
那么怎么解决呢?既然react自己没有处理,我们自己来包一个shallowEqual的实现:
export const Some = React.memo(function(props) {
...
})
我们在原来的Some组件外面包了一个React.memo,就可以让Some组件自动具备props的shallowEqual判断,当组件传入的props没有变化时,组件就不需要再次渲染。
2. 接收属性都相同的prop对象,怎么避免重新渲染?
很多情况下,我们使用组件时会直接传入一个对象,例如:
<Some info={{ name: 'toniy' }} />
这种用法会导致info每次都是一个新对象,组件每次都会重新渲染,有没有什么办法避免呢?
export const Some = React.memo(function(props) { ... }, (nextProps, prevProps) => {
return nextProps.info.name === prevProps.info.name
})
React.memo的第二个参数返回boolean,如果为true表示前后两次是相等的,相当于告诉react,这次组件不需要被重新渲染。
3. 避免回调函数引起重新渲染
对于onClick等事件回调,如果直接传入函数,也是被认为是一个全新的值,因此,用memo也无济于事。很多建议是通过useCallback或useEvent包裹回调函数,但我认为可以在组件内自己消化。
export const Some = React.memo(function(props) { ... }, (nextProps, prevProps) => {
return nextProps.onClick === prevProps.onClick || nextProps.onClick + '' === prevProps.onClick + ''
})
我们自己在组件内做好了优化,对于用该组件的人而言也是省心省力的。
4. 为什么组件的渲染似乎进入了死循环?
组件渲染开始后,浏览器假死,一直无法显示界面。很有可能是因为变更state导致的无限触发更新导致的死循环问题。可能的两种情况,一是在componentDidMount/componentDidUpdate中调用setState,二是在useEffect中调用setState。当组件完成渲染之后,你随即马上又调用setState来触发了组件的更新,而由于没有控制好,导致这一更新动作不断的被触发。
此时,你要检查setState是在什么情况下被调用。一方面可以通过shouldComponentUpdate来控制,再什么状态下可以更新组件,另一方面在setState之前做好if判断。
# React SSR
SSR技术主要针对首屏渲染,我们大部分前端应用都是通过构建大包进行发布,这就会导致应用首屏必须等到加载完对应的脚本,并执行之后,才会由react生成对应的DOM结构,并挂载到页面上。SSR技术则主要解决这一问题,简单讲,react的Virtual DOM可以在服务端运算出用于渲染的HTML字符串,从而让页面打开时,就已经具备了可渲染的html内容,用户也就能立即看到页面的内容。在这同时,页面还会继续加载对应的脚本,脚本完成之后,页面就恢复了正常的SPA效果。
不过SSR受限于后端运维的条件限制,并不适合所有前端场景。大部分情况下,我们可以结合serverless来运行ssr程序,同时在策略上做一些降级方案,保证ssr运行出错或后端机器卡顿时,可以退回到普通的CSR(客户端渲染)模式。
# Vue性能优化
Vue作为国人喜爱的一款前端框架,应用范围也很广泛。同时,与react相比,vue原生做了一些性能优化方面的工作,避免大部分开发者反复的去处理某些性能问题。但在vue使用过程中,偶尔我们也会遇到一些情况。
# Vue响应式原理
和react等框架不同,vue的编程特点是通过直接修改数据来触发界面的重新渲染。这一思想来源于angularjs,但是却比angularjs更加优秀,因为它采用了数据拦截的响应式原理,而抛弃了angularjs的脏检查机制。在vue2版本中,它通过Object.defineProperty来拦截数据,当在代码中直接修改数据(属性)时,会通过该属性的setter修改其值,在setter中,vue内置了一个触发界面更新的任务,等到下一帧时,这些更新任务就会被执行,从而带来界面的更新。在vue3版本中,它用Proxy替代了Object.defineProperty,因为Proxy可以更好的处理delete操作和数组的各种操作的拦截,但在拦截中插入重新渲染的任务仍然是其底层逻辑。
也正是因为这种拦截的机制,让vue在性能上,如果不做任何优化,会有比react性能更好的表现。因为这种拦截具有依赖收集的可能性(vue内部也是这么做的),也就意味着,只需要对依赖的变化进行响应即可,其他变化,即使是被拦截的数据,也无需对它进行响应。和react相比,react的重新渲染是全量的,一旦触发了更新,那么就是整个组件连带其子组件一起更新,而vue因为是根据哪一个数据变化来进行更新,所以在更新时具有更细粒度的把控,结合编译工具,可以做到只更新对数据有依赖的节点,这就使得其性能有不错的表现。但是,也正是由于它基于数据拦截机制,也带来了一些问题,一个问题是,当遇到一些无法被拦截的数据,例如一些类的实例对象,就无法正确响应其修改。
# 常见的Vue性能问题
1. 为什么修改某个数据时界面没有变动,却出现了卡顿?
由于数据拦截机制,会导致有些情况下,一些细节的修改我本不想带来重新渲染,但是由于其内部任务的存在,会出现大量的计算,占用CPU,而且vue不像react实现了时间切片,它就没有办法处理这种常见的CPU被大量占用的情况。针对这种情况,我们只需要让vue不要去拦截这类数据,即让这个数据不要具备响应式能力。我们可以用Object.defineProperty对数据提前进行定义,将其configurable设置为false,那么vue就无法通过Object.defineProperty来拦截该数据。
2. 为什么某个页面加载完数据之后,出现了严重卡顿?
因为可能是你的后端接口返回了一个巨大的数据,而你在往vue里面塞入该数据时,vue会对该数据进行初始化拦截处理,而由于数据太大,导致该过程消耗了大量的计算。解决办法是用Object.freeze把该数据进行冻结,经过冻结后的数据不会被vue拦截,这样就直接跳过了这个初始化拦截处理阶段,可以快速展示你的数据。
3. 大列表、大表格卡顿?
这个不是vue的问题,参见前面“虚拟视口技术”一节。
# 其他框架性能亮点
除了react和vue之外,其他一些框架在性能方面也有自己的一些亮点,这些亮点让这些框架在竞争激烈的前端领域独树一帜。
# Svelte为什么快?
2021年,svelte被评为react、vue、angular之后的第四大前端框架,主要原因在于它打破了react、vue一类框架的范式,没有一点和这些框架有相似的地方,相反,svelte大火之后,vue马上跟进,开始抄作业。在一些评测中,我们也可以看到svelte在性能上有不错的表现,它之所以快,主要有两个原因:
- svelte完全基于编译,它没有自己的运行时,虽然在编译结果中也存在一些运行时代码,但这些代码不足以称为一个框架,它完全通过编译来理解代码要做什么操作,并编译为执行该操作的代码,因此,svelte程序在运行的时候,不像vue或react,会有那么复杂的生命周期,也没有复杂的diff->patch等过程,因此就更快
- svelte抛弃了Virtual DOM,转而直接对DOM进行操作,基于上面一条原因,svelte没有像vue或react一样,构建一套virtual dom,由于构建virtual dom需要占用大量内存,同时还要基于virtual dom做大量运算,所以实际上是比较低性能的,由于没有virtual dom这一整套机制,svelte直接操作DOM,而且是一针见血的操作依赖变量的DOM节点,所以直捣黄龙搬的效率带来更高的性能
但是,svelte也存在一定的问题,由于它没有自己的运行时,导致每一个组件编译之后,都有大量相同或相似的运行时代码,这也就导致最终打包之后,代码体积可能比vue或react程序要更大。
# Solid为什么快?
solidjs是2021年火的一个框架,它身上集合了svelte的编译和无Virtual DOM、react的语法、vue的响应式原理等特点,这让它在前端框架届独树一帜。它之所以快,其实和svelte有相同的原因,虽然写solid程序有点像写react,但是实际上它和react在思想上完全不同,可以说是只借鉴了react的语法,其他的全部是svelte和vue,例如它的通过类似vue一样的reactive机制来实现界面的重新渲染,它采用了svelte的编译时策略,以及无Virutal DOM直接定点更新DOM节点的优化等等。
# Webpack构建性能优化
Webpack作为现代前端重要的基础设施,对于打包构建有非常好的支持。但是,作为开发构建工具,它在性能上却并不如新出现的一些工具,这使得它饱受诟病。我们可以通过有些手段来优化webpack构建性能,从而在开发或构建时拥有更好的开发体验。
# Webpack构建原理
虽然webpack的功能目标很单一,即把一堆代码打包后产生出一个可用的代码(或几个代码文件),但是,它的架构却极为复杂,不是一般初学者可以掌握的。简单讲,webpack是通过3个方面的体系实现其构建目标的,分别是:Compilition、Loader、Plugin。
其中Compilition是其最核心的部分,它完成了一个机器的核心设计,即完成内容转换+资源合并的能力,包含三个阶段:初始化阶段,构建阶段,生成阶段。其中,构建阶段又是重中之重,这个过程在我看来,本质上就是一个编译过程,只不过它的编译不是把一份代码转化为另一份,而是把一组代码转化为另外一组。它的构建大致如下:
- 创建Module
- runLoaders
- 用acorn讲js解析为AST
- 遍历AST,过程中还会收集依赖
- 处理依赖,创建依赖树
- 如果过程中通过插件等Module中新增了依赖,回流到第一步
- 如此循环往复,知道所有依赖都解析完毕
依赖树是webpack构建阶段的目标,后面的生成阶段则是基于该依赖树生成最终的chunks。而在生成依赖树之前或过程中,它会执行整个构建中的无数(200多个)钩子,这些钩子可以被插件挂载,从而影响整个构建流,比如插件可以加入新的依赖、替换依赖等等。在构建过程中,webpack会把每一个import/require认为是在引入一个Module,至于这个Module真正的文件类型它并不关心,因为它会把这个Module的识别交给Loaders去处理(当然,它默认可以识别js这种module),而一个loader也可以在返回的结果中增加依赖,这就导致webpack的构建过程会出现循环往复的过程,当然,你也可以说这是它先进的地方。
由于篇幅限制,我们只要掌握webpack三大体系是如何协作的,就可以大致了解webpack的构建原理。你也可以阅读这篇文章 (opens new window),了解更加详细的webpack构建原理。
# Webpack常见性能问题与优化技巧
通过上述原理,你可以发现,webpack的整个构建链路是很长的,而且它每一个阶段都需要执行大量计算,甚至还会循环往复的执行,所以性能上肯定好不到哪里去。但是,Compilition是我们无法修改的,它是webpack的核心,除非我们自己fork一份webpack的源码,定制一个自己的webpack。那么,能够优化的,就是通过插件、Loader的优化来提升性能了。
# 合理优化Loaders
我们知道webpack把每一个文件都当做Module对待,这也意味着,每一种文件类型,都需要一个(或多个)Loader来识别,并转化为ESModule的形式,比如图片要转化为 export default 'http://xxx/a.jpg' 这样的形式。但是,有些loader却会做多余的事,比如我们只是想得到一个url,但是它却去计算尺寸大小颜色等,浪费大量计算资源。一个典型的例子就是,不少开发者不管什么情况下,管他三七二十一,都把babel-loader加上,而且给babel配置了一大堆presets,这就导致js文件不仅要过babel的编译,还要过webpack的解析,当然更消耗性能。其实,在某些场景下,我们可以不需要babel-preset-env之类的babel插件或preset,只需要加几个用于识别特定的webpack无法识别的语法的插件即可,甚至一些情况下,如果我们写的代码是标准代码,不包含ESNext,那么不使用babel-loader也完全没有问题,毕竟标准ES是浏览器支持的。
# 启用多线程
我们知道webpack是基于js开发的,js是单线程的,所以即使两个毫不相干的loader也只能前后排队等待处理。我们可以利用happypack插件来启用多线程,让某些不需要串行的任务可以并行执行,这样就可以让某些loader可以同时运行,进而提升其性能。
# 使用DLL
动态链接库(DLL)是windows系统的一种方案,你可以利用webpack内置的DllPlugin插件,把一些固定不变的依赖,如放在node_modules目录下的模块文件的代码,打包的dll文件中,然后在编译时,基于dll的生成结果,webpack就不会再去打包这些依赖,由于减少了对这些依赖代码的整套构建流,所以整体的工作量就少了很多,性能也就提升了上来。
# 启用缓存
webpack5提高了更高水平的缓存机制,新版本的webpack为了在性能上有所突破,设计了一种复杂的缓存策略,它把一个Compilition整条链路都给分任务的缓存起来,每一个loader或plugin的执行,在每一个阶段的结果,都给缓存了一遍,当第二次进行编译的时候,如果它基于缓存检查到某个文件发生了变化,那么它不会去管其他文件的所有编译过程,而只会动当前文件的编译链,其他文件的所有编译结果将被直接使用。这一策略从理论上,显得非常高效,可以说是我所见过的缓存策略里面做的最彻底的。但是由于它要缓存的内容太多了,导致它的缓存文件特别大,动不动就上G了。而且另外一个方面,它的Compilition链路实在是太长了,即使其他所有文件的编译过程结果都无需重新生成,但是当前文件的编译链路也很长,这就导致即使使用了这么高级的缓存策略,webpack仍然无法做到秒级构建响应。
# 让webpack打出更小的包
随着项目增长,webpack打包的体积也越来越大。此时,我们要考虑用户打开页面时,下载代码文件所花掉的时间,因此,我们要想办法,让打包体积变小,让用户更快看到界面。基于webpack,我们有如下的方案:
- 使用dll
- 自己定制策略进行chunks拆分
- 使用动态引入import()
- 使用tree shaking能力
- 使用公共utils库,减少重复代码
- 避免同一依赖的多个版本被同时打包(当然,必要的情况下不得不依赖多个版本)
# 热重载
热重载(Hot Module Reload, HMR)是一种在更新代码后不刷新页面可以立即预览变更的技术,对于一些布局、样式的变化,非常有必要。
# HMR的原理
热更新的本质,就是一个函数的执行效果被这个函数的拷贝的执行效果覆盖。比如我们现在有一个函数 a() 在页面上输出"a",然后我们重新定义了函数 a() 在页面上输出"b",那么怎么做到页面不刷新而界面变化呢?运行新的 a() 就可以了。
HMR的本质思路也是这样。只不过它重载的不是函数,而是模块,当然,在webpack中,一个模块实际上也被包在一个函数中。但是如果我们脱离webpack聊HMR,那么其本质大致相同。一般来讲,HMR需要按照如下的原理来进行:
- 服务端:向客户端提供JS脚本,脚本具有特殊性质,里面包含了一些hmr的处理代码,客户端运行该JS脚本,运行后这个脚本就具备了hmr能力
- 服务端:监听文件变化,文件发生变化之后,重新进行构建,得到新的Module代码,这个新代码将被发送给客户端
- 服务端:得到新代码之后,通过websocket向客户端告知新代码产生了,快来拿
- 客户端:接收到服务端端websocket消息之后,通过jsonp获得新Module
- 客户端:从原来的模块依赖关系中,删除原始的模块引用,把新的Module作为替换,放到原始引用的位置
- 客户端:模块间的引用是一种软引用,从而能够保证模块引用发生变化时,其他模块再次获得该模块的接口时,获得的是新模块的接口
- 客户端:调用update方法,重新执行引用新Module的代码,从而使界面更新。这个update过程,可能需要开发者自己写代码来确定自己要调用哪个方法来更新界面。
虽然原理看上去很简单,但是要实现这一整套逻辑,且保证不出错,还是需要非常强大的编程能力才能做到。
无论如何,通过HMR,我们可以让用户看到的界面可以快速更新到最新代码想要得到的效果,这对于我们开发者而言,在开发调试阶段可以说是一把锋利的宝剑,为我们节省非常多时间。
# HMR状态丢失问题
如果你理解了 a() 被重载后执行来覆盖界面的本质,那么也就会发现,假如某些东西我们依赖的是 a() 内部的状态,那么 a() 被重载执行之后,原来的状态就会丢失。我们来举个例子:
function a() {
let state = { value: 1 }
html`
<span>${state}</span>
<input :bind=${state} />
`
}
上面的代码是基于一种html标签函数实现的前端渲染能力,当在输入框中输入数据时,它会更新state,并且带来界面的变化。可是现在如果我们重载了 a() 并重新运行它:
function a() {
let state = { value: 1 }
html`
<span>now: ${state}</span>
<input :bind=${state} />
`
}
我们就会发现,a() 运行后,state 回到了1,这也就导致now: 后面是1,但实际上我们希望它保持我们上一次输入的值,这也就是状态丢失了。怎么办呢?我们只要确保 state 是在 a() 外面定义即可解决这个问题。
在HMR的实际案例中,这种情况非常常见,因为作为HMR的提供者,是无法确保状态被用在什么地方的。因此,我们很少在实际生产环境使用HMR,更多是在开发环境中使用它。
# esbuild、vite等新事物
# 其他原生语言开发前端工具链
2020年开始,前端社区出现了用其他语言开发前端工具链工具的现象,到2021-2022这一现象骤然火爆,并引发了新一代前端工具链都是由其他语言,甚至更低层的rust等系统级语言来开发的讨论。在这些讨论之下,总有一种前端快失业的错觉。用其他原生语言来编写前端工具链主要有两个点:1. 现代前端开发非常依赖工具链,随着这些工具越来越臃肿,作为工具,运行越来越慢,已经无法适应前端开发的快节奏;2. 此前所有前端工具都是由js写成,部分通过nodejs调用c/c++模块,这导致了这些工具慢,而使用其他更低层的语言来编写,可以成百倍的提升其运行性能。
其中,esbuild和SWC就是典型代表。ESBuild是Figma前CTO Evan Wallace基于GO语言开发,用于实现类似webpack一样的打包工具。由于GO语言原生支持高并发,因此,esbuild中的任务可以被拆分并行,同时,由于完全摒弃了JS社区,没有任何历史包袱,因此,其整体设计和架构都更加现代化,更不会出现webpack工具链中多个ast串来串去的情况。SWC是由Rust语言实现的类似babel的编译器,不过它的官方网站上并没有详细阐述其内部实现,只提到了比JS的单线程而言,它具有并发优势。
由此可见,通过其他语言来开发前端工具链,最主要的一点,是绕开了JS单线程的缺点,同时原生语言更接近底层,不需要一个运行时,减少了额外的开销,因此性能上更优。但是不可否认的一点是,这些其他语言写就的工具,由于缺乏JS社区的支持,未来如何发展还很难讲,因为JS社区是非常活跃的,要让这些前端开发者切换语言去为其他语言的工具贡献,可能并不是一件容易的事。
# bundless
2021年,vue的作者尤雨溪在状态中称vite将超越webpack,而在2022年它也确实做到了非常大的占有率,甚至它的前辈snowpack都直接在自己的官网上推荐自己的用户去使用vite,要知道nowpack可以说是bundless的先驱,vite就是受其启发而创建的。
所谓bundless,简单讲,就是我们尽量不要去做类似webpack一样的打包,让我们的代码直接运行起来。没有了打包这个过程,其速度自然就快了很多。vite作为今年最热门的工具项目,它有自己的一些优势。vite是如何做到比webpack快的呢?对于webpack-dev-server而言,要在本地启动一个服务作为开发的预览服务,它必须进行一次webpack的打包过程,我们前文已经讲过,webpack其实是很慢的,虽然webpack-dev-server采用了内存文件系统,但是架不住其计算过程控制流太长太不可控,所以仍然会比较慢,开发者修改完代码之后,无法尽快看到修改后的效果。而vite则在本地服务中不执行打包过程,它基于ES原生的Module系统,也就是import from语法在浏览器中的原生支持,让浏览器自己去请求一个依赖,而请求的依赖实际上是向vite本地服务的一个url地址发起请求,vite本地服务在接收到这个请求之后,立马对该请求所对应的文件进行编译和输出,这个效率和我们经常提到的SSR差不多,这也就让vite在第一次打开时比webpack快了n倍,因为对于vite而言,第一次打开时,要做的事情非常少,只需要起一个服务,把被访问的脚本编译完吐出就可以了,在页面发生变化的时候,新的请求过来,才会执行新的编译。
虽然vite在开发时效率极高,但是并不代表它就是前端工具的终极形态,bundless在浏览器原生支持import的今天,其实是非常尴尬的,我们很难预判在不久的将来,我们还需要bundless,我们可能只需要浏览器就可以了。